
「导语」 当我们创建了 Keras 模型并开始进行训练时,一般都会指定一些超参数(如学习率)的值来对训练的过程进行调控,而这些超参数的取值会对模型训练的结果产生很大的影响,因此在机器学习工作流程中一项十分重要的步骤就是要确定模型超参数的最佳取值,亦即超参数调优。在 TensorFlow 中,我们可以使用 HParams 插件很方便地完成这一调优过程。
什么是超参数
机器学习和深度学习的模型中往往包含成千上万个参数,其中有的参数可以通过模型训练并利用反向传播算法来进行优化,比如模型中的权重 (weights) 和偏差 (bias) 等,我们称之为参数 (parameters)。还有一些参数不能通过模型训练来进行优化,比如学习率 (learning rate) 、深度神经网络中的隐含层 (hidden layers) 的个数以及隐含层的神经元 (hidden units) 个数等,我们称之为超参数 (hyper parameters)。
超参数是用来调节整个模型的训练过程的,它们只是配置变量,并不直接参与到训练的过程中,因此需要我们不断调整与尝试,以使得模型效果达到最优。需要注意,在一次训练迭代的过程中,参数是不断进行更新的,而超参数是恒定不变的。
一般而言,我们会根据模型在训练集和验证集上的损失大小,以及预定义的评估指标来选择最优超参数组合,并最终将该组超参数应用于正式训练以及线上的 Serving 服务。
超参数调优策略
模型的超参数一般都有很多,而且每个超参数也会有众多的候选值,形成的参数空间较大,如果仅依赖人工逐项测试,时间和精力成本无疑是巨大的,因此有许多自动调参算法被提出。
目前比较常用的超参数自动调优策略包括网格搜索 (grid search) 和随机搜索 (random search) 等。
网格搜索
- 网格搜索是指在所有候选的超参数取值中,尝试所有的超参数组合,并选取其中使模型效果达到最优的超参数组合作为最终解。
- 比如模型有
2个超参数,每个超参数有3个候选值,那么所有的超参数组合就有3*3=9种,网格搜索会尝试所有9组超参数并从中选择最佳组合。 - 网格搜索的缺点是,模型训练评估的次数会随超参数数量以及超参数候选值数量的增加而呈指数级增长,从而产生很高的算力和时间成本,因此它并不适用于超参数的数量及候选值数量较多的情况。
随机搜索
- 随机搜索是指每次选取随机的超参数组合进行尝试,它可以手动设置尝试的次数,避免遍历整个超参数空间,从而可以减少尝试的成本。
- 相比网格搜索,随机搜索能够更高效地进行超参数调优,但是随机搜索并不能保证一定能选取到最优的超参数取值,具有不确定性。
HParams 超参数调优步骤
TensorFlow 提供了 HParams 插件来辅助我们进行超参数调优, HParams 插件支持网格搜索和随机搜索两种策略。下面以 Keras 模型训练为例,介绍使用 HParams 进行超参数调优的步骤。
定义超参数
- 使用
HParam类初始化定义所有的超参数,并指定超参数的取值域 (Domain)。Domain有三种类型,一种为IntInterval表示连续的整数取值,Discrete表示离散取值,可以是整数,浮点数以及字符串等,RealInterval表示连续的浮点数取值。 - 例
HP_DEEP_LAYERS = hp.HParam("deep_layers", hp.IntInterval(1, 3))表示连续的整数取值的超参数,1为最小值,3为最大值,取值范围是[1, 3]。 - 例
HP_DEEP_LAYER_SIZE = hp.HParam("deep_layer_size", hp.Discrete([32, 64, 128]))表示离散取值的超参数,可以取参数列表 (list) 中的任一元素。 - 例
HP_LEARNING_RATE = hp.HParam("learning_rate", hp.RealInterval(0.001, 0.1))表示连续的浮点数取值的超参数,0.001为最小值,0.1为最大值,取值范围是[0.001, 0.1]。
定义评估指标
- 使用
Metric类定义我们要用到的评估指标,后面会根据这些指标来选取最优的超参数组合。 - 例
hp.Metric("epoch_auc", group="validation", display_name="auc (val.)")表示要用到的评估指标为epoch_auc。指标必须是被Tensorboard回调函数记录的或者自定义的标量 (scalar) ,一般存储在日志文件中,可视化展示时会被HPARAMS面板调用并显示。 Metric构造函数的第一个参数tag表示指标的名称,对于使用Tensorboard回调函数 (callbacks) 记录的指标,其名称一般为epoch_tag或batch_tag,如epoch_auc。对于自定义的指标,tag则为tf.summary.scalar("test_auc", auc, step=1)中设定的名称,这里为test_auc。Metric构造函数的第二个参数group表示指标存储的路径,比如训练的指标存储在train目录下,验证的指标存储在validation目录下,自定义的指标可以存储在test目录下等,详见示例程序。Metric构造函数的第三个参数display_name表示指标在HPARAMS面板中显示的名称。
配置 HParams
- 通过
hp.hparams_config(hparams=HPARAMS, metrics=METRICS)可以按需设置将要选取的超参数以及用于评估的指标。 hparams_config方法有两个参数,它们分别表示所有待选超参数HParam的列表 (list) 和所有评估指标Metric的列表 (list) 。- 如果不进行此项全局设置,
HParams默认会记录所有在模型中使用到的超参数以及模型输出的所有指标值并在HPARAMS面板中显示。
构建超参数模型
一般是是将超参数以字典 (
dict) 的形式传递给模型构造函数以完成模型的构建。模型构造函数的代码如下所示:
def model_fn(hparams):
model = keras.models.Sequential()
for _ in range(hparams[HP_DEEP_LAYERS]):
model.add(
keras.layers.Dense(
units=hparams[HP_DEEP_LAYER_SIZE],
activation="relu",
use_bias=True,
))
model.add(keras.layers.Dense(units=1, activation="sigmoid"))
model.compile(
optimizer=tf.keras.optimizers.Adam(
learning_rate=hparams[HP_LEARNING_RATE]),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=["AUC"],
)
return model超参数字典的
key为上面定义的HParam对象,value为基本数据类型的值。模型的构建过程与一般模型构建相同,只不过将原来固定的参数换成超参数字典中的
value值。当然,也可以预先定义好一个可配置的subclass模型,然后将超参数传入该模型,即可更加方便地完成模型的构建。
模型训练
- 模型训练时需要指定
fit方法的callback参数,不仅需要包含Tensorboard回调函数,还需要包括hp.KerasCallback回调函数。 - 其中第一个回调函数用于记录损失 (
loss) 以及指标 (metrics) 的值,第二个回调函数用来记录本次训练使用的超参数组合以及计算最后的损失值以及指标值。 hp.KerasCallback(logdir, hparams)中第一个参数为记录HParams日志的目录,第二个参数为超参数字典,与传递给模型构造函数的字典相同。- 如果使用某组超参数执行了多次训练,那么最终
HPARAMS面板的显示结果为多次评估结果的平均值。
可视化调参结果
如果进行
2次超参数选择,其日志根目录mlp的结构如下所示:mlp
├── 0
│ ├── events.out.tfevents.1589257272.alexander.4918.34.v2
│ ├── test
│ │ └── events.out.tfevents.1589257274.alexander.4918.2418.v2
│ ├── train
│ │ └── events.out.tfevents.1589257272.alexander.4918.95.v2
│ └── validation
│ └── events.out.tfevents.1589257273.alexander.4918.1622.v2
├── 1
│ ├── events.out.tfevents.1589257274.alexander.4918.2575.v2
│ ├── test
│ │ └── events.out.tfevents.1589257275.alexander.4918.4958.v2
│ ├── train
│ │ └── events.out.tfevents.1589257274.alexander.4918.2636.v2
│ └── validation
│ └── events.out.tfevents.1589257274.alexander.4918.4162.v2
└── events.out.tfevents.1589257272.alexander.4918.5.v2其中
0和1目录分别存储了一组超参数训练与验证后的结果数据。模型的训练和验证结果(包括
loss以及metrics) 会以events.out.tfevents文件的形式保存在Tensorboard回调函数指定的目录下,本示例中为0或1目录下的train和validation目录。HParams记录的日志会保存在0或1根目录下的events.out.tfevents文件中。启动
Tensorboard并指定其logdir参数为mlp,然后选择HPARAMS面板即可看到可视化的调参结果。
完整超参数调优示例
网格搜索示例
网格搜索需要遍历所有的超参数组合,所以此时在初始化 HParam 超参数对象时应该尽量使用 Discrete 域类型,方便数据遍历。当然 IntInterval 和 RealInterval 域类型的数据也可以通过指定步长的方式来进行遍历。
如果超参数对象的域类型是 IntInterval 和 RealInterval 时,可以通过该对象的 domain.min_value 和 domain.max_value 属性获取超参数候选值的最小值和最大值。如果是 Discrete 类型,可以通过 domain.values 属性获取到该超参数所有候选值的列表 (list)。
网格搜索的示例代码如下所示(搜索步骤参见 run_all 函数):
import os |
随机搜索示例
通过调用超参数对象的域 (domain) 属性的 sample_uniform() 方法可以从该超参数的候选值中随机选取一个值,然后就可以使用随机生成的超参数组合进行训练了。
sample_uniform 方法还可以接收一个带有种子 (seed) 的伪随机数生成器,如 random.Random(seed),这在分布式训练的超参数调优过程中十分重要,通过指定同一个伪随机数生成器,可以保证所有 worker 节点每次获取到的超参数组合都是一致的,从而确保分布式训练能够正常进行。
随机搜索 run_all 部分的代码如下所示,其它部分的代码与网格搜索相同。
def run_all(logdir): |
HPARAMS 面板
启动 Tensorboard 后,即可在页面的上方看到 HPARAMS 选项,点击该选项就能够看到 HPARAMS 面板 (Dashboard) 了。
HPARAMS 面板提供了左右两个窗格,左边的窗格提供了筛选功能,右边的窗格提供了可视化评估结果的功能,下面来分别对它们的功用进行说明。
筛选窗格
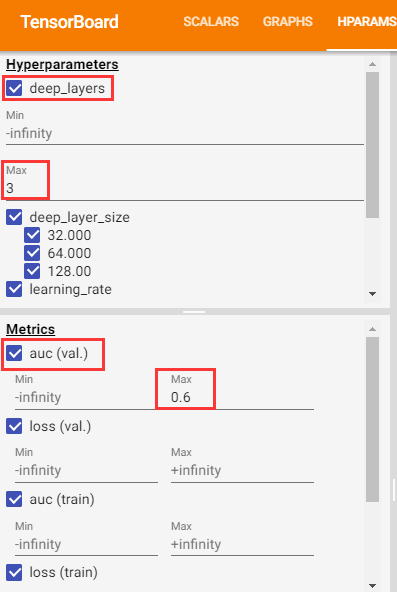
筛选窗格提供了筛选功能,以控制右边窗格的可视化渲染。它可以选择用于展示的超参数以及指标,可以筛选被展示的超参数以及指标的值,还可以对可视化的结果进行排序等。如下图所示:
可视化窗格
可视化窗格包含三个视图 (view) ,分别包含不同的信息。
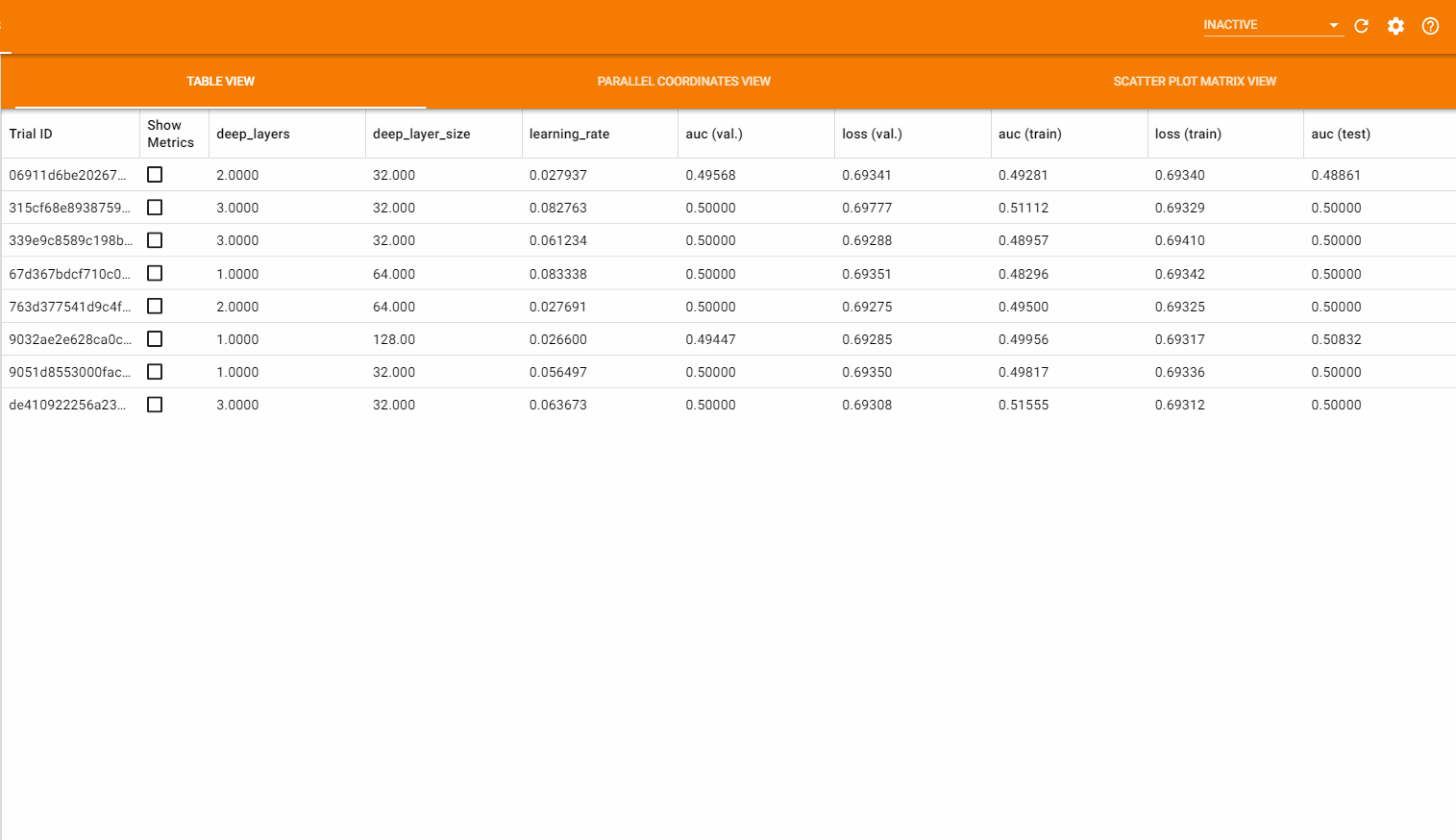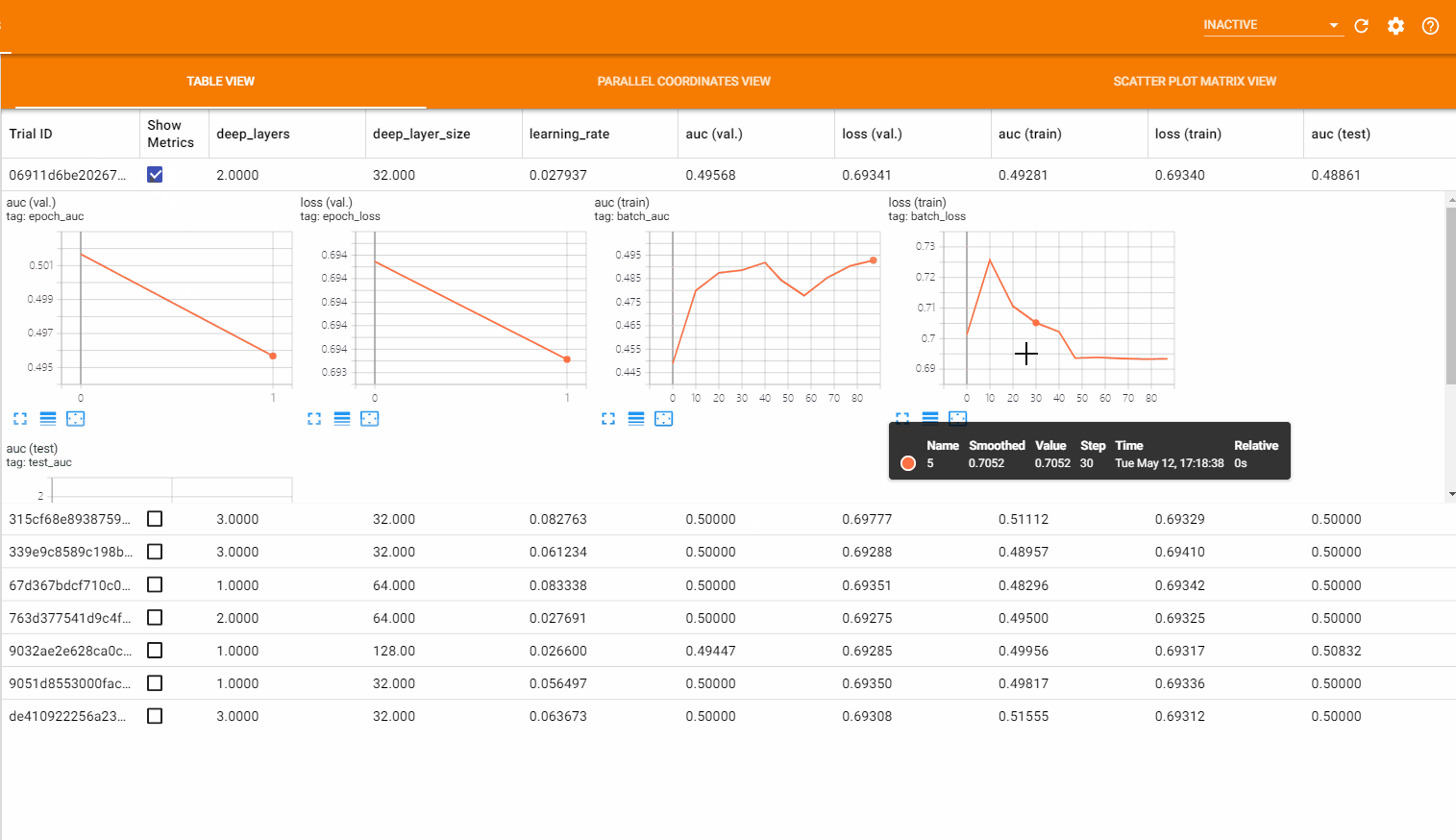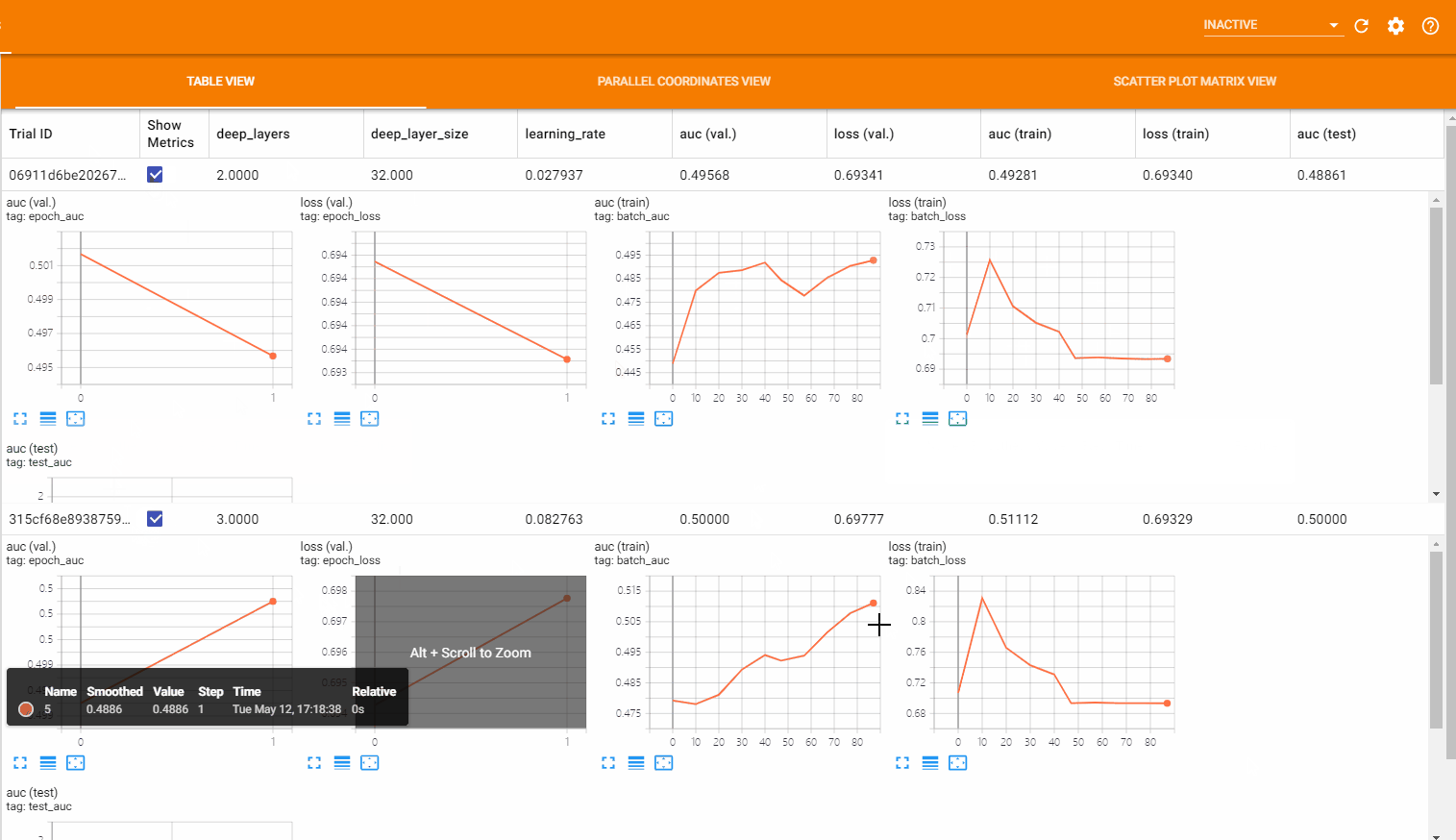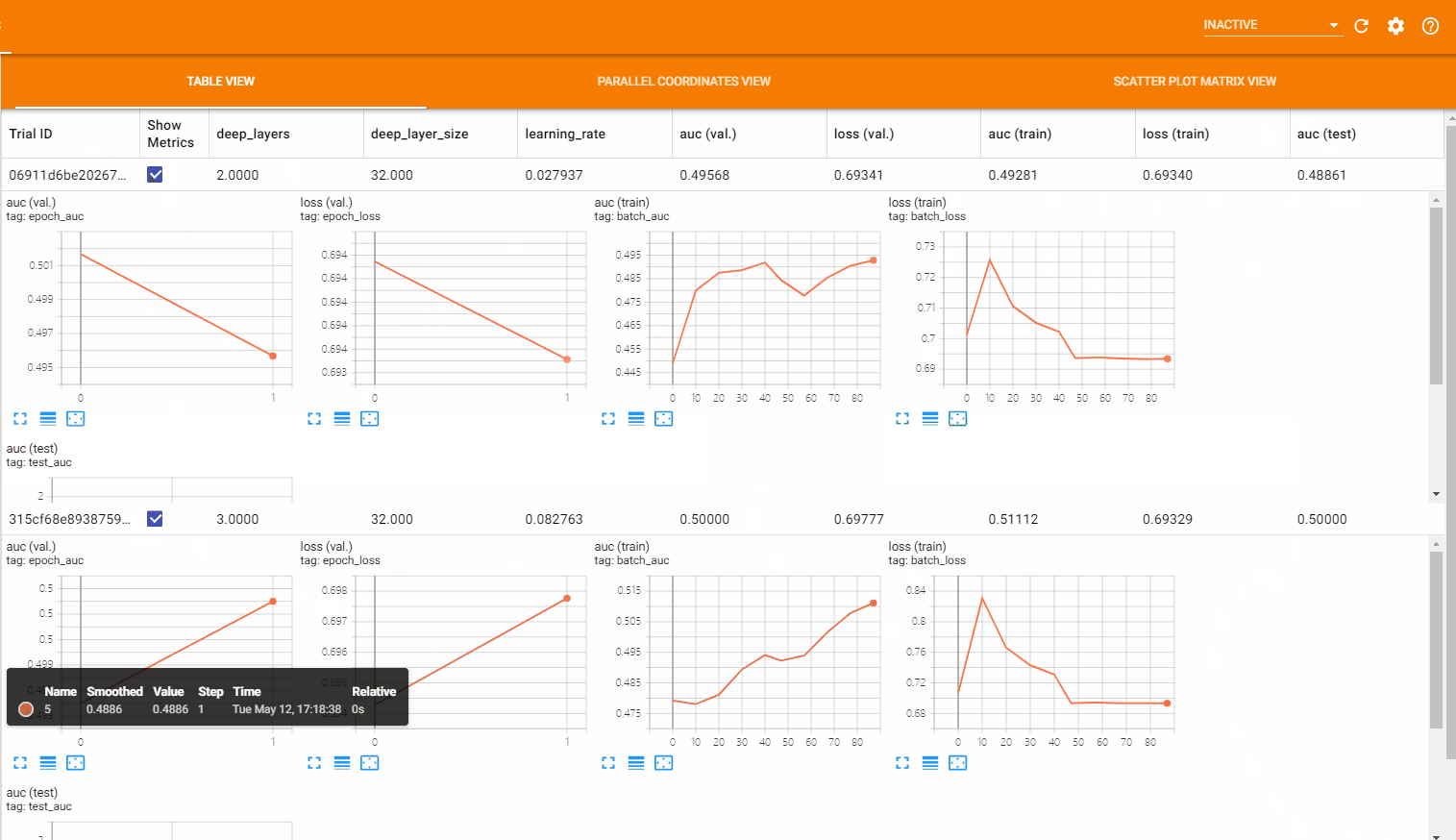
表格视图 (Table View) 以表格的形式列出了所有的超参数组合以及对应的各项指标的值,还可以通过点击 Show Metrics 来展示指标随 batch 或 epoch 的变化趋势图。如下图所示:
平行坐标视图 (Parallel Coordinates View) 由一系列表示超参数和指标的竖向坐标轴组成,对于每一超参数的取值以及对应的指标值,都会通过一条线连接起来。点击任意一条线都会对该组取值进行高亮显示,可以在坐标轴上用鼠标标记一个区域,这时只会显示在该区域内的取值,这对于判断哪组超参数更为重要十分有帮助。如下图所示:

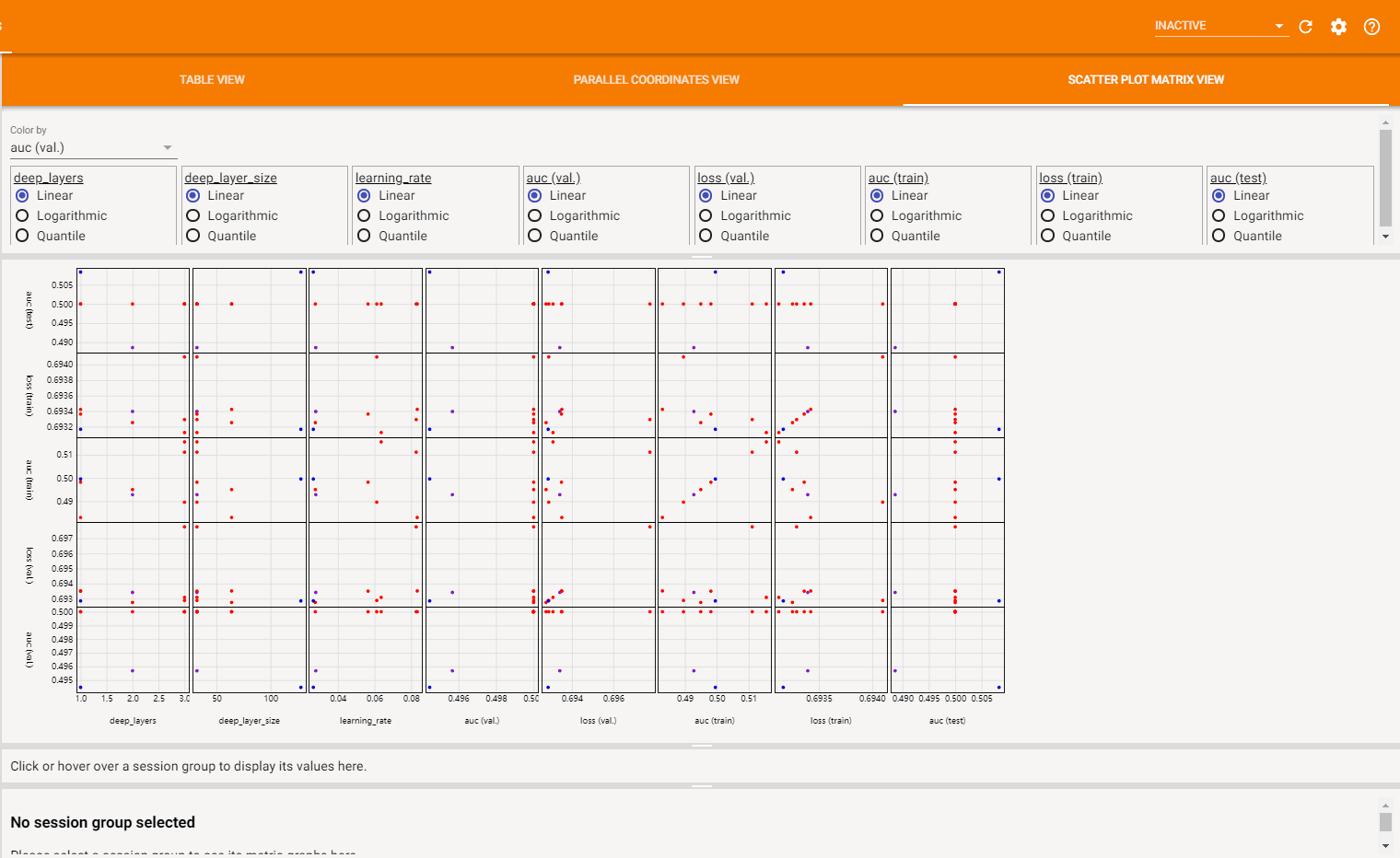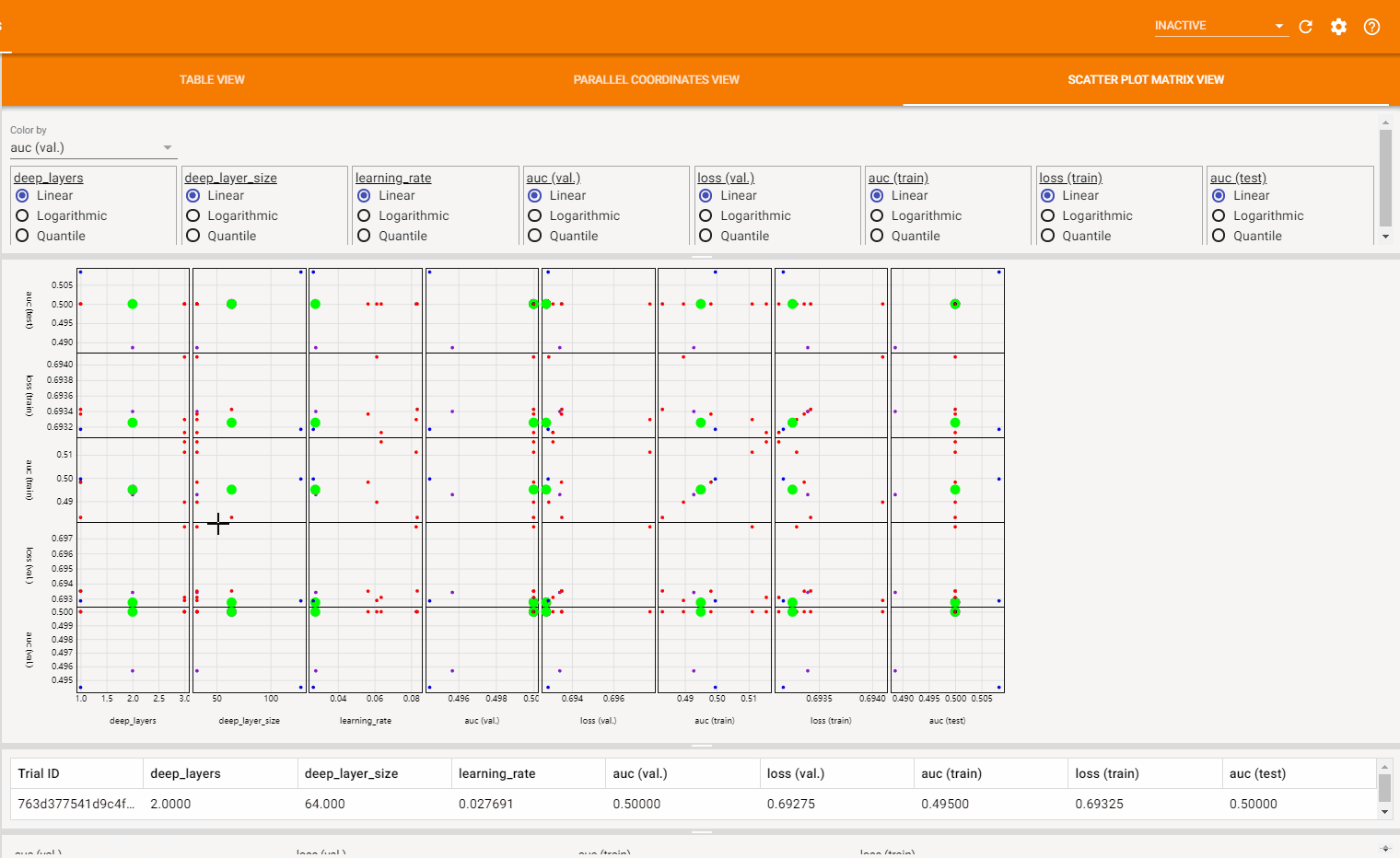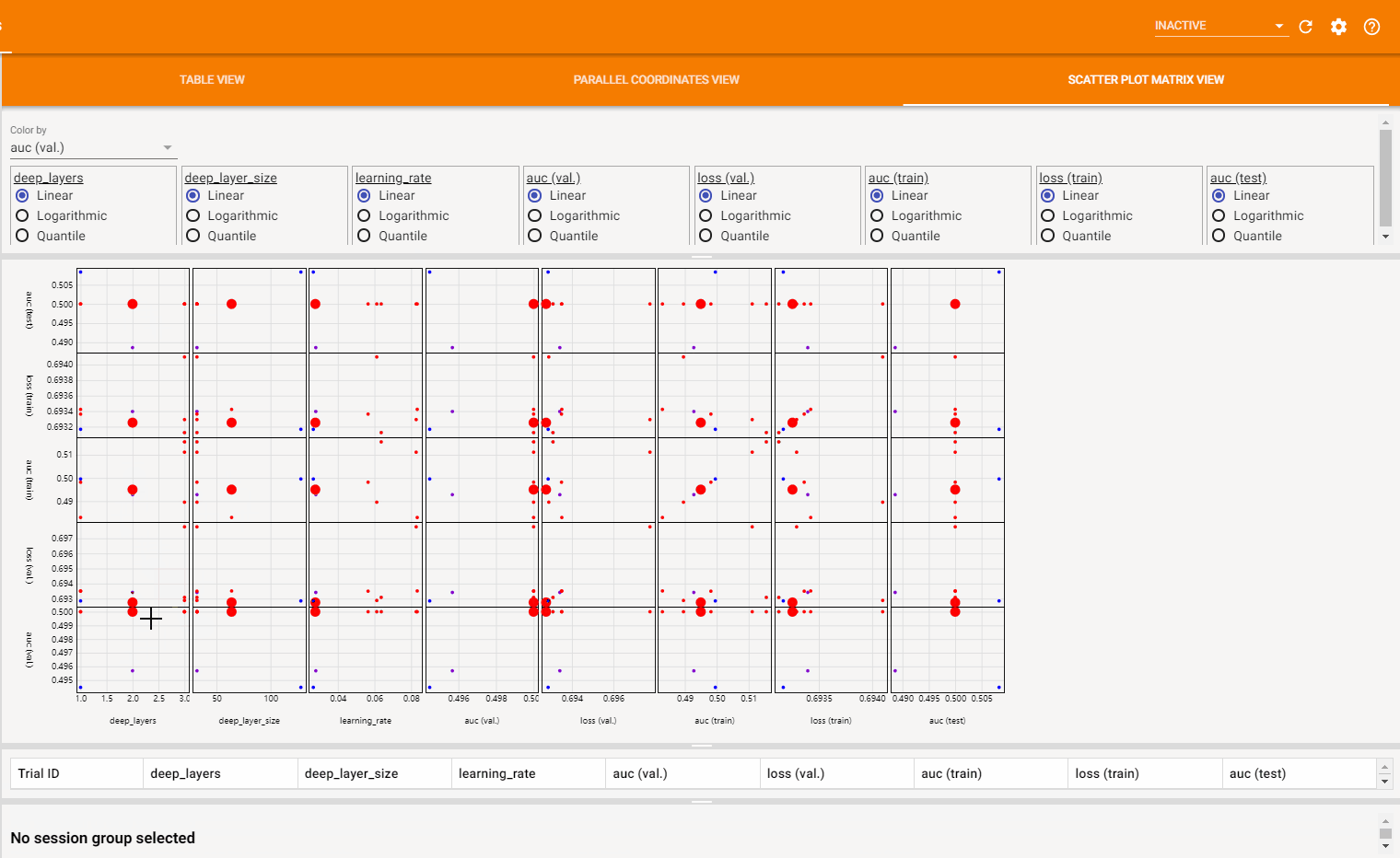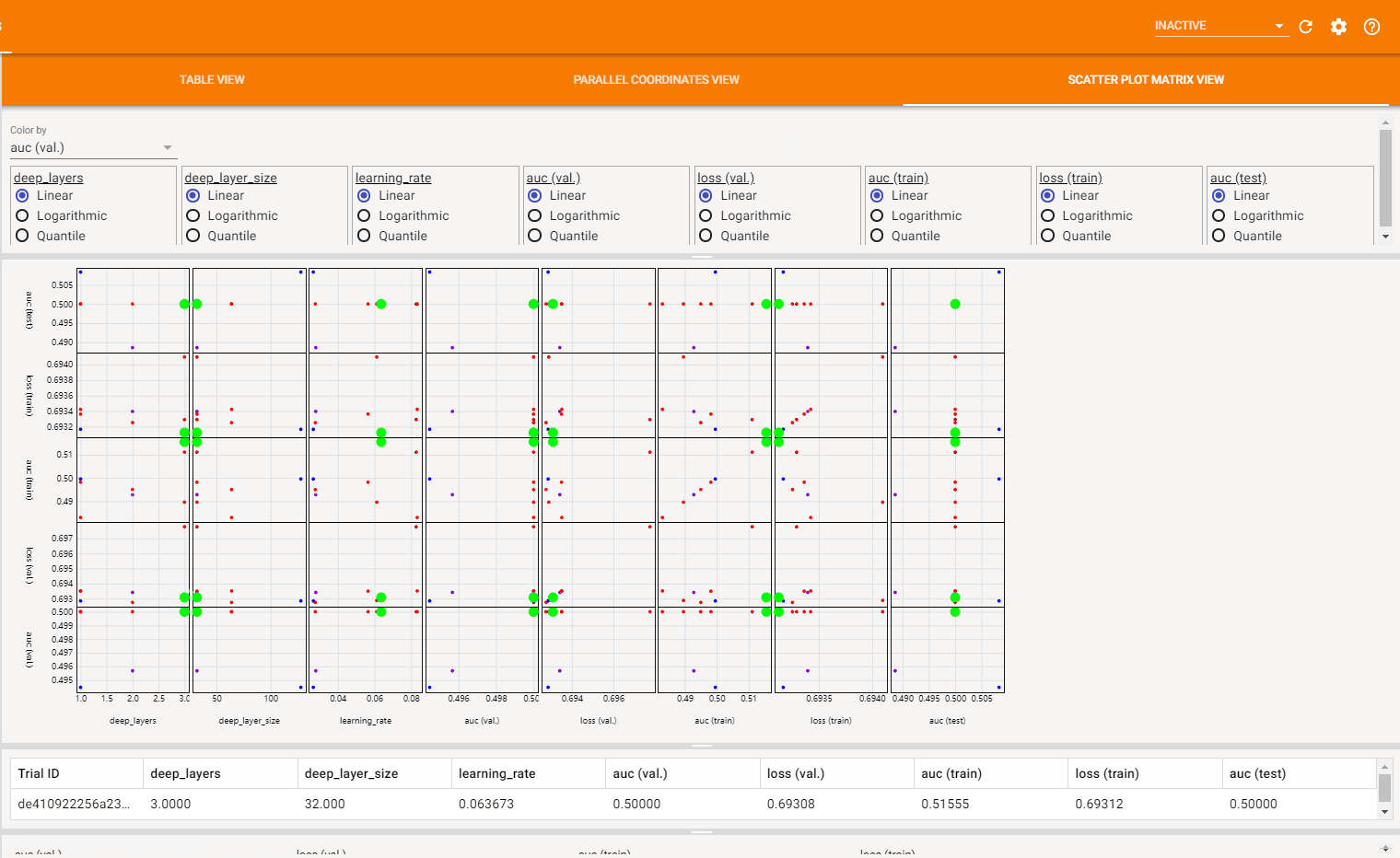
散点图视图 (Scatter Plot View) 由一系列超参数与指标之间关联的散点图组成,它可以帮助发现超参数之间或超参数与指标之间的潜在关联。如下图所示:
注意事项
RealInterval的取值如果从0开始,则要以浮点数0.形式表示。- 每一组超参数都需要独立的训练过程,所以要将不同组超参数训练的日志文件写到不同的目录下。
- 在进行超参数调优时,模型训练方法
fit中的metrics参数要设置为字符串类型或者一个全局的Metric对象。这样Tensorboard记录的metrics名称才能在多次训练中保持一致如epoch_auc,而不会出现epoch_auc_1,epoch_auc_2这种情况,从而使得HPARAMS面板能够正常获取到metrics的值并进行展示。 - 在分布式训练中进行超参数随机搜索时,需要指定一个带种子的伪随机数生成器,使得每个
worker节点选取到的随机值都一致,从而确保分布式训练能够正常进行。
参考资料
- Hyperparameter Tuning with the HParams Dashboard
- Hparams demo
