
「导语」 Clickhouse 是一个高性能且开源的数据库管理系统,主要用于在线分析处理 (OLAP) 业务。它采用列式存储结构,可使用 SQL 语句实时生成数据分析报告,另外它还支持索引,分布式查询以及近似计算等特性,凭借其优异的表现,ClickHouse 在各大互联网公司均有广泛地应用。
Why ClickHouse
OLAP
首先我们来看一下 OLAP 场景下的关键特征。
大多数数据库访问都是读请求。
数据总是以批量形式写入数据库(每次写入大于
1000行)。已添加的数据一般无需修改。
每次查询都从数据库中读取大量的行,但是同时又仅需少量的列。
数据表多为宽表,即每个表均包含着大量的列。
查询量一般较少(非高并发,通常每台服务器每秒约有数百个查询或更少)。
对于简单查询,允许的延迟大约为
50毫秒(响应时间要迅速)。列中的数据相对较小,一般为数字或短字符串。
处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)。
事务不是必须的。
对数据一致性要求低。
查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被存放在单台服务器的内存中。
可以看到,OLAP 业务场景与其它流行的业务场景如 OLTP 等有很大的不同,使用 OLTP 数据库或 Key-Value 数据库去处理分析查询业务将会获得非常差的性能,而且没有任何意义。
另外,相比于行式数据库,列式数据库则更适用于 OLAP 场景,因为对于大多数的查询而言,列式数据库的处理速度要至少比行式数据库快 100 倍,我们可以通过下面的数据查询图来直观理解。
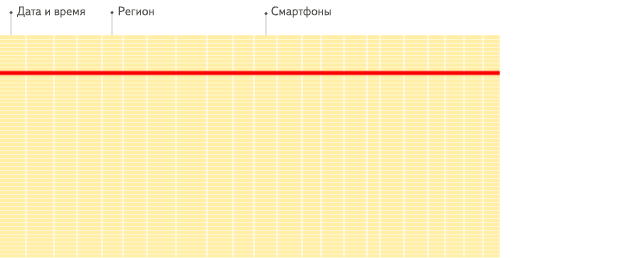
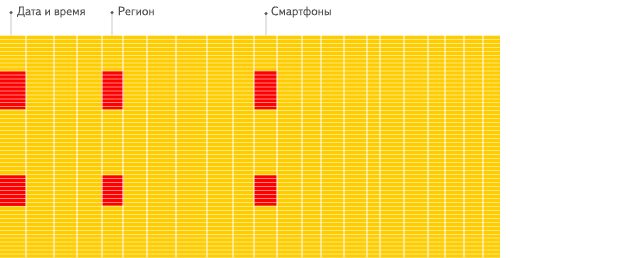
从图中可以看到,二者的性能差别很大,列式数据库明显占优,可以从以下几方面来解释:
对于分析类查询,通常只需要读取数据表中的一小部分列,使用列式数据库可以很轻松地实现,而使用行式数据库却必须要读取全部的列,这就带来了性能的损失。
列式数据库按列存储数据,使得数据更容易被压缩,可以降低
I/O传输的体积,从而使查询速度加快。由于
I/O体积的降低,可以使得更多的查询数据被系统缓存,进一步加快了查询的速度。另外,执行一个查询一般需要处理大量的行,在整个列向量上执行所有操作将比在每一行上执行所有操作更加高效,而且还可以更加充分地利用
CPU资源,从而提升了查询的性能。
ClickHouse 特性
相比于其它的列式数据库,ClickHouse 的以下特性决定了它更适用于 OLAP 业务场景。
数据压缩:
ClickHouse会自动对插入的数据进行压缩,这对于性能的提升起到了至关重要的作用。磁盘存储:
ClickHouse被设计为工作在传统磁盘上,这意味着数据存储的成本较低。多核心并行处理:
ClickHouse会利用服务器的一切必要资源,从而以最自然的方式并行化处理大规模查询。分布式查询:在
ClickHouse中,数据可以保存在不同的分片 (shard) 上,查询可以在所有分片上并行处理。支持
SQL:ClickHouse的查询语言大部分情况下是与SQL标准兼容的,更容易上手。向量引擎:
ClickHouse采用了列向量引擎技术,可以更为高效地使用CPU资源。实时数据更新:
ClickHouse使用MergeTree引擎对数据进行增量排序,数据可以持续不断地写入到表中并进行合并,而且在整个过程中不会存在任何加锁行为。支持索引:
ClickHouse按照排序键对数据进行排序并支持主键索引,可以使其在几十毫秒内完成对特定值或特定范围的查找。支持近似计算:
ClickHouse提供了许多在允许牺牲数据精度的情况下对查询进行加速的方法。
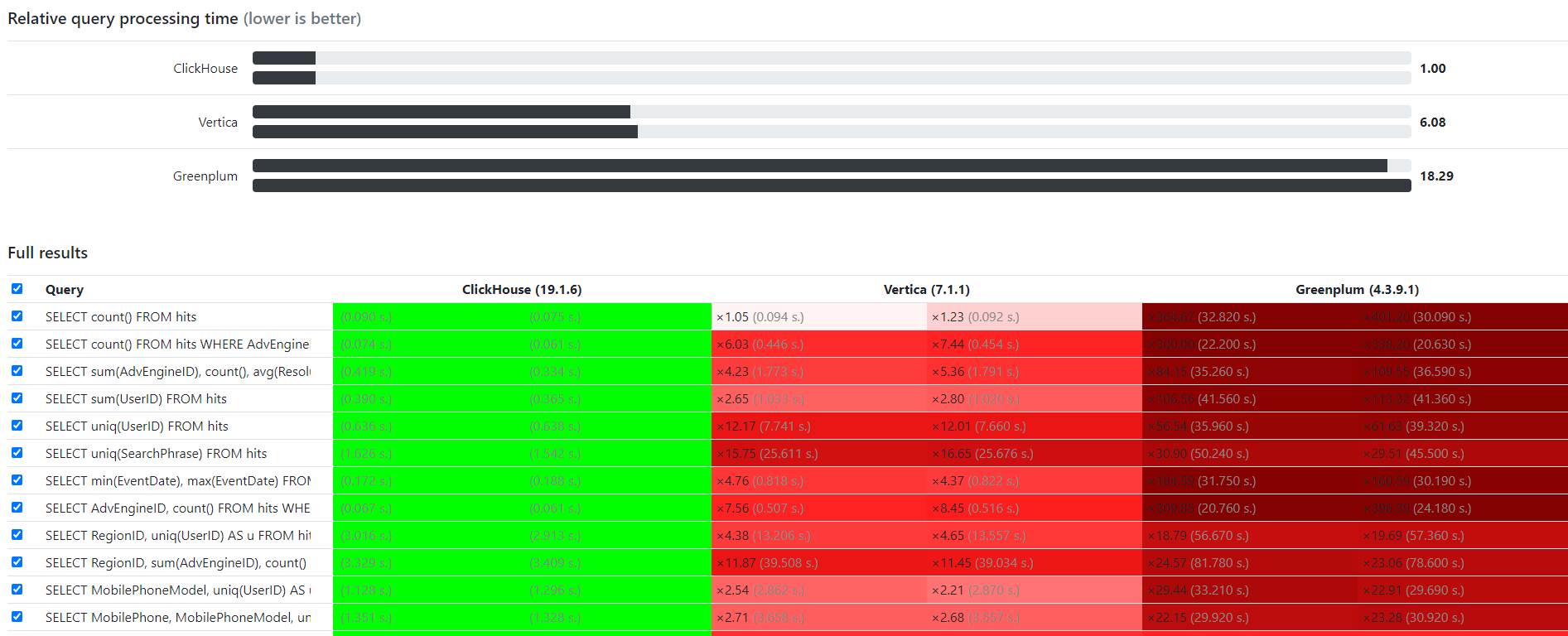
下图显示了 ClickHouse 与其它主流列式数据库的性能对比。可以看到,对于大多数查询而言,ClickHouse 的响应速度更快,这也是选择 ClickHouse 作为 OLAP 数据处理的主要原因。
ClickHouse 安装 (CentOS)
首先安装最新版本
ClickHouse。添加官方仓库
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo
安装 server 和 client
sudo yum install clickhouse-server clickhouse-client启动
clickhouse-server服务,这里使用systemctl命令以service的方式启动ClickHouse。sudo systemctl start clickhouse-server
使用
systemctl启动的好处是当ClickHouse服务由于某些异常宕掉后系统会自动重启该服务。使用客户端工具查看
ClickHouse启动是否成功。clickhouse-client
ClickHouse client version 20.3.7.46 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.3.7 revision 54433.
hostname :)从客户端的输出中可同时查看
Server以及Client的版本,一般而言二者的版本需保持一致,否则可能会带来一些兼容性问题。需要注意,对于已经存有大规模数据 (
T级别)的ClickHouse节点,每次启动均需要花费一定的时间,主要用来加载数据分片,因此启动的时间主要取决于数据分片的多少,可通过系统表system.parts来查询分片的数量。在数据加载过程中(
Server未完全启动)如果使用clickhouse-client客户端来连接ClickHouse会报如下错误:Code: 210. DB::NetException: Connection refused (localhost:9000),需等待数据加载完成后方可正常连接。
ClickHouse 配置文件
在使用 ClickHouse 之前,我们需要修改 ClickHouse 配置文件中的一些默认配置,比如数据存储路径,集群信息以及用户信息等,这样可以更好地对 ClickHouse 进行管理控制,以满足我们的业务需求。
配置说明
ClickHouse支持多配置文件管理,主配置文件为config.xml,默认位于/etc/clickhouse-server目录下,其余的配置文件均需包含在/etc/clickhouse-server/config.d目录下。ClickHouse的所有配置文件均是XML格式的,而且在每个配置文件中都需要有相同的根元素,通常为<yandex>。主配置文件中的一些配置可以通过
replace或remove属性被其子配置文件所覆盖,如子配置文件中的<zookeeper replace="true">表示将使用该配置来替换主配置文件中的zookeeper选项。如果两个属性都未指定,则会递归组合各配置文件的内容并替换重复子项的值。另外,配置文件中还可以定义
substitution替换,如果一个配置包含incl属性,则替换文件中相应的配置将被使用。默认情况下替换文件的路径为/etc/metrika.xml,可以通过include_from配置项进行设置。如果待替换的配置不存在,ClickHouse会记录错误日志,为了避免这种情况,可以指定配置项的optional属性来表示该替换是可选的,如<macros incl="macros" optional="true" />。在启动时,
ClickHouse会根据已有的配置文件生成相应的预处理文件,这些文件中包含了所有已完成替换和覆盖的配置项,它们被统一放置于preprocessed目录下,你可以从这些文件中查看最终的配置项是否正确。另外ClickHouse会跟踪配置文件的更改,对于某些配置如集群配置以及用户配置等,更改后会自动生效,无需重启ClickHouse服务,而对于其它配置项的更改可能需要重启服务才能生效。对于集群中的全部
ClickHouse节点,除部分配置(如macros)外,其它所有的配置最好都保持一致,以便于统一管理及使用。
数据路径配置
数据路径下既存储数据库和表的元数据信息(位于
metadata目录)也存储表的真实数据(位于data目录)。元数据是指建库和建表的语句,亦即数据库和表的结构信息,每次ClickHouse启动时会根据元数据信息去加载相应的数据库和表。数据路径的配置如下所示,其对应的
XML标签为<path>。<path>/path/to/clickhouse/</path>
当单个物理盘无法存储全部的数据时,可以考虑将不同的数据库存储在不同的物理盘上,然后在
/path/to/clickhouse/data/目录下创建软连接指向其它物理盘上的数据库目录。
日志配置
ClickHouse的日志文件中记录了各种类型的事件日志,包括数据的插入和查询的日志以及一些配置和数据合并相关的日志等。一般我们会通过日志文件找出ClickHouse报错的具体原因,以便解决问题。日志的配置如下所示,其对应的
XML标签为<logger>。<logger>
<level>trace</level>
<log>/path/to/clickhouse-server/clickhouse-server.log</log>
<errorlog>/path/to/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>level表示事件的日志级别,可以配置为trace,debug,information,warning,error等值。log表示主日志文件路径,该日志文件中包含所有level级别以上的事件日志。errorlog表示错误日志文件路径,该日志文件仅包含错误日志,便于问题排查。size表示日志大小,当日志文件达到指定size后,ClickHouse会进行日志轮转。count表示日志轮转的最大数量。需要注意,因为事件日志是由多线程异步写入到日志文件中的,所以不同事件之间的日志会产生交错,不利于按顺序进行日志排查。但
ClickHouse为每个事件都提供了唯一的ID来标识,我们可以根据此ID来跟踪事件状态的变化。
集群配置
集群的配置主要用于分布式查询,在创建分布式表 (
Distributed) 时会用到。集群配置文件的示例如下所示,其对应的
XML标签为<remote_servers>。<yandex>
<remote_servers>
<cluster_name>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>hostname1/ip1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>hostname2/ip2</host>
<port>9000</port>
</replica>
</shard>
</cluster_name>
</remote_servers>
</yandex>cluster_name表示集群名称,shard表示集群的分片(即ClickHouse节点),集群会有多个shard,每个shard上都存有全部数据的一部分。weight表示数据写入的权重,当有数据直接写入集群时会根据该权重来将数据分发给不同的ClickHouse节点,可以理解为权重轮询负载均衡。replica表示每个shard的副本,默认为1个,可以设置多个,表示该shard有多个副本。正常情况下,每个副本都会存有相同的数据。internal_replication表示副本间是否为内部复制,当通过集群向分片插入数据时会起作用,参数的默认值为false,表示向该分片的所有副本中写入相同的数据(副本间数据一致性不强,无法保证完全同步),true表示只向其中的一个副本写入数据(副本间通过复制表来完成同步,能保证数据的一致性)。在实际情况下,我们一般不会通过集群进行数据写入,而是将数据直接写入到各
ClickHouse节点。一来通过集群进行分发数据会带来二次的网络延迟,降低了数据的写入速度,二来当数据量较多时,由于网络带宽限制,数据分发节点会成为数据传输的瓶颈,从而拉低了整体的数据写入效率。可以定义多个集群,以应对不同的查询需要。每次添加新的集群配置后,无需重启
ClickHouse服务,该配置会即时生效。
字典配置
字典就是一种键->值映射关系,一般在数据查询时使用。相比于多表
JOIN的查询操作,使用字典查询会更加高效。字典文件的位置需要由
config.xml文件中的dictionaries_config配置项设置。<dictionaries_config>dictionaries/*_dictionary.xml</dictionaries_config>
上述配置表示
ClickHouse会从与config.xml文件同级的dictionaries目录下加载以_dictionary.xml为后缀的全部字典文件。字典配置文件的示例如下所示,其对应的
XML标签为<dictionary>。<yandex>
<comment>An optional element with any content.</comment>
<dictionary>
<name>dict_name</name>
<source>
<!-- Source configuration -->
<file>
<path>/path/to/clickhouse/dictionaries/os.tsv</path>
<format>TabSeparated</format>
</file>
</source>
<layout>
<!-- Memory layout configuration -->
<complex_key_hashed />
</layout>
<structure>
<!-- Complex key configuration -->
<key>
<attribute>
<name>key</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>value</name>
<type>String</type>
<null_value></null_value>
<injective>true</injective>
</attribute>
</structure>
<lifetime>300</lifetime>
</dictionary>
</yandex>name表示字典名称。source表示字典的数据来源,数据来源有多种类型,可以是本地的文本文件,HTTP接口或者其它各种数据库管理系统。layout表示字典在内存中的存储方式。一般推荐使用flat,hashed和complex_key_hashed存储方式,因为它们提供了最佳的查询处理速度。structure表示字典的结构,亦即键值对的信息。key表示字典的键值,它可以由多个属性组成。attribute表示字典的值,也可以有多个。
lifetime表示字典的更新频率,单位为秒。创建完字典后,我们就可以通过
SELECT dictGet[TYPE]('dict_name', 'value', tuple('key'))语句来查询字典中指定key值对应的value了。其中TYPE表示具体的数据类型,比如获取字符串类型的值可以使用dictGetString。除了使用配置文件来创建字典外,还可以使用
SQL语句来生成字典。但相对而言,使用配置文件会更加直观便捷。
用户配置
config.xml可以指定单独的文件来对用户信息进行配置,用户配置文件的路径通过users_config配置项指定,默认为users.xml。<users_config>users.xml</users_config>
与
config.xml文件类似,用户配置也可以被切分为不同的文件以便于管理,这些文件需要保存到users.d目录下。ClickHouse的默认用户为default,密码为空。用户配置的示例如下所示,其对应的
XML标签为<users>。<users>
<!-- If user name was not specified, 'default' user is used. -->
<user_name>
<password></password>
<!-- Or -->
<password_sha256_hex></password_sha256_hex>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>profile_name</profile>
<quota>default</quota>
</user_name>
<!-- Other users settings -->
</users>user_name表示待添加的用户名。password表示明文密码,不推荐使用该方式设置密码。password_sha256_hex表示经过sha256 hash后的密码,推荐使用该方式设置密码,密码的生成方式如下所示。echo -n "$PASSWORD" | sha256sum | tr -d '-'
networks表示允许连接到ClickHouse节点的网络地址列表,可以为IP地址或Hostname。::/0表示该用户可以从任何网络地址连接到ClickHouse节点。profile表示对用户的一系列设置,用以控制用户的行为,如设置该用户具有只读权限等。它是以单独的XML标签存在于users.xml文件中的。配置的示例如下所示。<!-- Settings profiles -->
<profiles>
<!-- Default settings -->
<default>
<!-- The maximum number of threads when running a single query. -->
<max_threads>8</max_threads>
</default>
<!-- Settings for quries from the user interface -->
<profile_name>
<!-- Maximum memory usage for processing single query, in bytes. -->
<max_memory_usage>30000000000</max_memory_usage>
<!-- How to choose between replicas during distributed query processing. -->
<load_balancing>in_order</load_balancing>
<readonly>1</readonly>
</profile_name>
</profiles>profile的名称可以任意,不同的用户可以配置相同的profile。另外需要注意,default profile必须存在,它会在ClickHouse启动时作为默认的设置使用。quota表示用户配额设置,用来限制用户一段时间内的资源使用,如1小时内的查询数不超过1024等。它同样是以单独的XML标签存在于users.xml文件中的。配置的示例如下所示。<!-- Quotas -->
<quotas>
<!-- Quota name. -->
<default>
<!-- Restrictions for a time period. You can set many intervals with different restrictions. -->
<interval>
<!-- Length of the interval. -->
<duration>3600</duration>
<!-- Unlimited. Just collect data for the specified time interval. -->
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>配额限制与
profile中限制的主要区别在于,它可以对一段时间内运行的一组查询设置限制,而不是限制单个查询。除了使用配置文件管理用户,还可以基于
SQL语句来创建、修改或删除用户。但相对而言,使用配置文件会更加直观便捷。
ZooKeeper 配置
zookeeper配置允许ClickHouse与一个ZooKeeper集群进行交互。ClickHouse主要使用ZooKeeper来存储复制表的元数据,当不使用复制表时,该配置可以忽略。ZooKeeper配置文件的示例如下所示,其对应的XML标签为<zookeeper>。<yandex>
<zookeeper replace="true">
<node index="1">
<host>hostname1/ip1</host>
<port>2181</port>
</node>
<node index="2">
<host>hostname2/ip2</host>
<port>2181</port>
</node>
<node index="3">
<host>hostname3/ip3</host>
<port>2181</port>
</node>
</zookeeper>
</yandex>node表示一个ZooKeeper节点,可以设置多个。当尝试连接到ZooKeeper集群时,index属性指定了各节点的连接顺序。
Macros 配置
macros配置主要用来替换复制表的参数,在创建复制表时需要用到,当不使用复制表时,该配置可以忽略。Macros配置文件的示例如下所示,其对应的XML标签为<macros>。<yandex>
<macros replace="true">
<shard>01</shard>
<replica>hostname/ip</replica>
</macros>
</yandex>
Prometheus 配置
该配置用来供
Prometheus获取ClickHouse的指标信息。Prometheus配置的示例如下所示,其对应的XML标签为<prometheus>。<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
</prometheus>endpoint表示指标接口的URI。port表示指标服务所使用的端口。metrics,events和asynchronous_metrics都是标志项,代表是否暴露相应的指标信息。配置完成后,即可访问
http://ip:port/metrics来查看所有的ClickHouse指标信息了。
MergeTree 配置
该配置用来对使用
MergeTree系列引擎的表进行微调。需要注意,除非你对该配置有充分的了解,否则不建议修改。MergeTree配置的示例如下所示,其对应的XML标签为<merge_tree>。<merge_tree>
<!-- If more than this number active parts in single partition, throw 'Too many parts ...' exception. -->
<parts_to_throw_insert>300</parts_to_throw_insert>
</merge_tree>更多
MergeTree相关配置可以参见源码中的MergeTreeSettings.h头文件。
其他常用配置
时区配置。
<timezone>Asia/Shanghai</timezone>
最大连接数配置。
<max_connections>4096</max_connections>
并发查询数配置。
<max_concurrent_queries>200</max_concurrent_queries>
ClickHouse最大内存使用量配置。<max_server_memory_usage>0</max_server_memory_usage>
可删除表的最大数据量配置。
<max_table_size_to_drop>0</max_table_size_to_drop>
单位为字节,默认值为
50 G,当表中数据大小超过该限制时,不能使用DROP语句去删除该表(防止误操作)。如果设置为0,表示没有任何限制。如果你仍然想删除某个数据量超限的表而不想修改上述配置并重启
ClickHouse时,可以在ClickHouse的数据目录下创建一个标志文件/path/to/clickhouse/flags/force_drop_table表示可以强制删除该表,然后执行DROP语句即可删表成功。需要注意上述标志文件在执行完一次
DROP语句后会被自动删除以防止再次执行意外的DROP操作,因此执行创建标志文件和执行DROP语句的系统用户(非ClickHouse用户)应该保持一致,以避免在执行完DROP语句后,用户没有权限删除标志文件,从而导致后续操作失误并造成数据损失。更多的配置可参见其官方文档,然后再按需调整。
ClickHouse 表引擎
ClickHouse 的表引擎是 ClickHouse 服务的核心,它们决定了 ClickHouse 的以下行为:
数据的存储方式和位置。
支持哪些查询操作以及如何支持。
数据的并发访问。
数据索引的使用。
是否可以支持多线程请求。
是否可以支持数据复制。
ClickHouse 包含以下几种常用的引擎类型:
MergeTree引擎:该系列引擎是执行高负载任务的最通用和最强大的表引擎,它们的特点是可以快速插入数据以及进行后续的数据处理。该系列引擎还同时支持数据复制(使用Replicated*的引擎版本),分区 (partition) 以及一些其它引擎不支持的额外功能。Log引擎:该系列引擎是具有最小功能的轻量级引擎。当你需要快速写入许多小表(最多约有100万行)并在后续任务中整体读取它们时使用该系列引擎是最有效的。集成引擎:该系列引擎是与其它数据存储以及处理系统集成的引擎,如
Kafka,MySQL以及HDFS等,使用该系列引擎可以直接与其它系统进行交互,但也会有一定的限制,如确有需要,可以尝试一下。特殊引擎:该系列引擎主要用于一些特定的功能,如
Distributed用于分布式查询,MaterializedView用来聚合数据,以及Dictionary用来查询字典数据等。
MergeTree
MergeTree 系列引擎是 ClickHouse 所有表引擎中最强大的引擎,该系列引擎提供了用于弹性和高性能数据检索的大多数功能,包括列式存储,自定义分区以及主键索引等。
MergeTree 系列引擎旨在高效处理大规模数据,该系列引擎可以将数据以分片 (parts) 的形式快速地写入表中,并按照一定的规则在后台对这些分片进行合并,相比于在插入时不断重写已有数据,这种数据合并的策略会更为高效。
MergeTree 引擎具有如下特点:
存储的数据按排序键排序:这使你能够创建一个小型的稀疏索引来加快数据检索。
支持数据分区:查询中指定了分区键时
ClickHouse会自动截取分区数据,可以有效增加查询的性能。数据复制:
ReplicatedMergeTree系列的引擎提供了数据复制功能。数据采样:可以给表设置一种采样方法,便于全局采样。
使用 MergeTree 引擎创建表的语法如下所示:
ENGINE = MergeTree() |
ENGINE子句表示引擎名称和参数。ORDER BY子句指定排序键,可以为一组列名或任意的表达式,如ORDER BY (CounterID, Date)。另外如果没有使用PRIMARY KEY指定主键,会默认使用排序键作为主键。PARTITION BY子句指定分区格式(可选),默认为按月分区,如果要按天分区可以使用PARTITION BY toYYYYMMDD(date_column),那么最终的分区格式则为YYYYMMDD。PRIMARY KEY子句指定主键(可选),大部分情况下无需专门指定,会与排序键相同。SAMPLE BY子句指定采样的表达式(可选),采样表达式必须包含在主键里。TTL子句指定表中数据存储的持续时间(可选),满足时间条件后会执行相应的操作,如数据删除或数据移动等。SETTINGS子句指定MergeTree引擎的一些其它参数,如索引粒度index_granularity=8192等。排序键与主键的不同之处在于,排序键用来对数据分片进行排序,而主键用来建立索引。在多数情况下,我们不会额外指定主键,此时排序键和主键是完全一致的,它们既可以用来排序数据,也可以用来建立索引。而在一些特殊情况下(如
SummingMergeTree),会使用多数的列作为排序键,相应的数据索引可能会很稠密,数据查询性能也会很差,此时可以使用PRIMARY KEY子句来单独指定主键,一般而言,会选取排序键的一个子集作为主键,因为数据已经按排序键排好序,这样建立的数据索引就会很稀疏,查询性能也会大幅提升。
示例语句如下所示。
ENGINE = MergeTree() |
在该例子中,我们设置了按月进行分区,同时我们设置了一个按哈希后的 UserID 进行采样的表达式。如果你在 SELECT 查询时指定了 SAMPLE 子句,ClickHouse 就会返回一个均匀伪随机分布的用户子集。
MergeTree 引擎可以被视为 ClickHouse 节点的默认表引擎,该系列的其它引擎都是在 MergeTree 引擎的基础上为某些特定的用例添加了额外的功能而实现的。
ReplacingMergeTree
ReplacingMergeTree 引擎与 MergeTree 引擎的不同之处在于它会删除排序键相同的数据项,亦即数据去重。去重工作只会在数据合并期间进行,而数据合并的时间是不定的,因此,在查询时可能仍有排序键相同的数据。
ReplacingMergeTree 引擎并不能保证没有重复的数据出现,因此它更适用于在后台清除重复的数据以节省空间。
另外 CollapsingMergeTree 和 VersionedCollapsingMergeTree 引擎也提供了数据去重的功能,与 ReplacingMergeTree 相比,它们的功能更为丰富,但使用的复杂度也有所增加,可以按需选择。
ReplacingMergeTree 的建表语法与 MergeTree 的建表语法基本一致,唯一需要注意的就是排序键的选择。
SummingMergeTree
SummingMergeTree 引擎与 MergeTree 引擎的不同之处在于当对 SummingMergeTree 表中的数据分片进行合并时,ClickHouse 会将所有具有相同排序键的行汇总为一行,行中具有数值类型的列将会被 SUM 求和。如果表中的每个排序键值都对应大量的行,那么使用该引擎可以显著地减少数据存储空间并加快数据查询速度。
因为数据合操作并不能保证具有相同排序键的行都在同一数据分片中,所以 SummingMergeTree 的汇总操作可能并不完整,在使用 SELECT 查询时应该使用 SUM() 聚合函数和 GROUP BY 子句以确保获得正确的结果。
在数据汇总时,数值类型的列都会被 SUM 求和,如果这些数值列的值均为 0,则该行会被删除。如果某列不在排序键中且为非数值类型,那么会从该列所有的值中任选一个进行汇总。
另外,如果想使用其它聚合函数对数值型的列进行汇总,可以考虑使用 AggregatingMergeTree 引擎。
SummingMergeTree 的建表语法与 MergeTree 的建表语法基本一致,在使用时我们最好将所有非数值类型的列都作为排序键,然后只对数值类型的列进行 SUM 求和。
数据复制
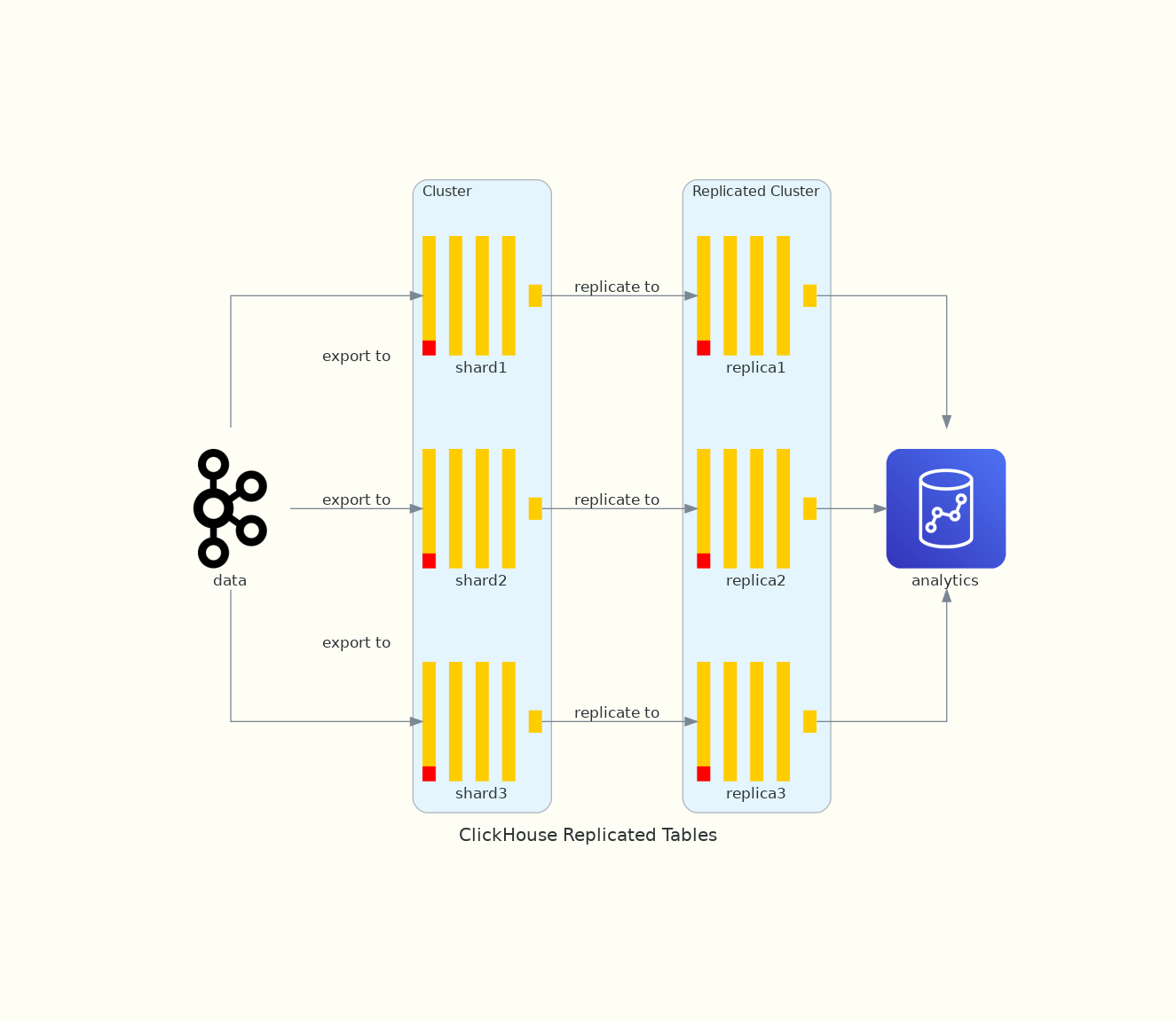
数据复制是 ClickHouse 的一项重要功能,因为它为数据存储与查询提供了更高的可用性。
上面介绍的 MergeTree 系列的引擎均可通过其相应的 Replicated 引擎来实现数据复制功能,如 ReplicatedMergeTree 和 ReplicatedSummingMergeTree 等。复制操作是表级别的,而不是整个服务器节点级别的,因此一个 ClickHouse 节点可以同时拥有复制表和非复制表。
在创建复制表前,我们需要确保已经在 config.xml 文件中添加了 ZooKeeper 配置并且 ZooKeeper 节点可以正常连接,否则将无法创建复制表。复制表的建表语法如下所示。
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/table_name', '{replica}') |
其中 /clickhouse/tables/{shard}/table_name 表示存储该复制表元数据信息的 ZooKeeper 节点路径,shard 和 replica 会使用相应的宏 (Macros) 值进行替换(在配置文件一节中介绍过)。对于同一个分片的不同复制表,其 shard 值应该保持一致,replica 值需要保证唯一。
在 ZooKeeper 的 /clickhouse/tables/{shard}/table_name/replicas/{replica}/host 节点上会存有该 replica 的连接信息,包括 hostname,端口,数据库名称以及表名等,这些信息是 ClickHouse 自动获取并推送到 ZooKeeper 的。在数据复制时,replica 之间会尝试使用 hostname 建立网络连接,如果 replica 之间无法通过 hostname 相互访问,那么它们之间的数据复制操作就会失败。
在对复制表执行 INSERT 和 ALTER 操作时,该操作是会被复制到其它副本同步执行的,而 CREATE,DROP,ATTACH,DETACH 和 RENAME 等操作只会在接收节点运行而不会被复制,在使用时需要注意。
在使用复制表进行查询时不需要借助于 ZooKeeper,其复本的数量也不会影响查询的性能,因此它的查询速度与查询非复制表的速度是一样的。而向复制表插入数据时,由于需要将元数据写入 ZooKeeper,所以相比于非复制表,其所需时间可能会更长一些。但只要你按照建议以每秒不超过一个 INSERT 的频率批量地插入数据,那么数据插入的速度基本与非复制表保持一致。
复制操作是多主异步的,因此可以将 INSERT 语句发送给任意的副本节点,插入操作会先在接收节点上执行,然后再复制到其它副本所在节点上执行。由于复制操作是异步的,不同副本之间的数据会有一定的延迟,延迟的时长为通过网络传输压缩数据块所需的时间。默认情况下,INSERT 语句仅会等待一个副本写入成功后就返回,如果要启用数据写入多个副本后才返回,可以使用 insert_quorum 选项。
对于被多次写入的相同数据块(大小相同且具有相同行和相同顺序的数据块),复制表会自动去重,因此把相同的数据块发送给多个副本也不会有问题。另外,数据复制期间,只有源数据是通过网络进行传输的,进一步的数据合并操作会在所有的副本上以相同的方式进行。
是否使用复制表可能与具体的业务相关,有时为了业务的高可用性,我们可能会将非复制表转为复制表,有时为了节省不必要的磁盘开销,我们也可能将复制表转为非复制表。
当需要把 MergeTree 表转换为 ReplicatedMergeTree 表时,可按如下步骤操作。
将
MergeTree表重命名,然后使用旧名称创建结构相同的ReplicatedMergeTree表。将数据从
MergeTree表的目录移动到ReplicatedMergeTree表目录的detached文件夹下。使用
ALTER TABLE ATTACH PARTITION ...操作将数据加载到ReplicatedMergeTree表中。如果数据量少的话,可以使用INSERT ... SELECT ...语句来完成该操作。删除
MergeTree表。
当需要把 ReplicatedMergeTree 表转换为 MergeTree 表时,可按如下步骤操作。
将
ReplicatedMergeTree表重命名,然后使用旧名称创建结构相同的MergeTree表。将数据从
ReplicatedMergeTree表的目录移动到MergeTree表的目录下。先使用
DETACH TABLE ..语句分离MergeTree表,然后再使用ATTACH TABLE ...语句挂载MergeTree表即可加载数据。同理,如果数据量少的话,可以使用INSERT ... SELECT ...语句来完成该操作。删除
ReplicatedMergeTree表。
数据分区
MergeTree 系列的表(包括复制表)均可以使用分区 (partition) 来管理数据,分区是指在一个表中通过指定的规则划分而成的逻辑数据集。我们可以按任意标准进行分区,比如按月,按天或按事件类型等。为了方便对表中的分区数据进行管理,各个分区在物理上都是分开存储的。在查询表中数据时,ClickHouse 会根据 WHERE 子句中的查询条件尽量使用所有分区的最小子集来检索数据以提升查询速度。
分区是在建表时通过 PARTITION BY expr 子句指定的,分区键可以是表中列的任意表达式。例如按月分区,表达式为 toYYYYMM(date_column)。另外分区键也可以是表达式元组,如 PARTITION BY (toMonday(date_column), event_type),表示我们按一周内的事件类型分区。
当有新数据插入到表中时,这些数据会存储为按排序键排序的数据分片 (parts),在数据插入后 10-15 分钟左右,属于同一分区的各个数据分片会进行合并。
需要注意的是在设置分区时,不能太过于精细(比如超过 1000 个分区),这会使文件系统上的数据分片(文件)数量过多,从而导致在数据合并时会消耗大量的系统资源,另外,在数据查询时也会打开过多的文件描述符,从而导致查询效率不佳。
我们可以通过系统表 system.parts 来查看表的分区和分片信息,假设我们有一个 visits 表,该表按月分区,查询 system.parts 表的语句及结果如下所示。
SELECT |
┌─partition─┬─name───────────┬─active─┐ |
partition表示分区的名称,示例中有两个分区202001和202002。name表示数据分片的名称,对于202001_1_3_1而言,202001表示分区名称,1表示数据块的最小编号,3表示数据块的最大编号,1表示块级别也就是该分片是合并的次数(亦即MergeTree的深度)。active表示数据分片的状态,1表示激活状态,0表示非激活状态。非激活分片是指那些合并后尚未删除的源数据分片以及损坏的数据分片,非激活的数据分片会在数据合并后的10分钟左右被删除。
查看分区和分片的另一种方法是进入表的数据目录。根据上面介绍的数据路径配置,数据表的文件系统目录应位于 /path/to/clickhouse/data/<database>/<table>/,数据目录的具体信息如下所示。
ls -l |
202001_1_3_1 和 202001_1_9_2 等文件夹都表示一个数据分片,每个分片都与一个对应的分区相关联,并且只包含这个分区的数据。
除了数据分片文件夹外,数据目录下还包含一个 detached 文件夹,该文件夹下包含了使用 ALTER ... DETACH ... 命令从表中分离的数据分片。ClickHouse 不会使用该目录下的数据,你可以手动对该目录下的数据进行各种操作。而对于其它目录下的数据则不建议手动操作,避免出现数据损坏,导致 ClickHouse 无法加载。
数据存储
数据表由不同的数据分区 (partition) 组成,分区的数据又会被分为不同的数据分片 (parts)。当有新数据插入到表中时,ClickHouse 会创建多个数据分片,在每个数据分片内,数据会按排序键的字典顺序排序,例如当排序键是 (CounterID, Date) 时,分片中的数据会首先按 CounterID 进行排序,然后具有相同 CounterID 的部分继续按 Date 进行排序。
在同一数据分区内,ClickHouse 会在后台不定期地合并数据分片以便更高效地存储,而不同分区的数据分片则不会进行合并,另外,合并机制并不能保证具有相同排序键的行全部都合并到同一个数据分片中,换言之每个分区最终可能会包含多个数据分片。
数据分片可以以 Wide 或 Compact 格式存储。在 Wide 格式下,表中的每一列都会在文件系统中存储为单独的文件,而在 Compact 格式下,表中所有的列都会存储在一个文件中。在插入的数据量少但很频繁时可以使用 Compact 格式存储以提升性能,在其它情况下都应使用 Wide 格式存储。存储格式的选择由 min_bytes_for_wide_part 和 min_rows_for_wide_part 两个参数控制,如果数据分片中的字节数或行数少于上述值则采用 Compact 格式存储。这两个参数可以在 SETTINGS 子句中设置,如果两者都不设置,则默认采用 Wide 格式进行存储。
每个数据分片在逻辑上会被分割为颗粒 (granules),也可以理解为数据块 (block)。颗粒是 ClickHouse 中进行数据查询时最小的不可分割数据集,每个颗粒都会包含整数行。每个颗粒的第一行会通过该行的主键值进行标记,ClickHouse 会为每个数据分片创建一个索引文件来存储这些标记。对于表中的每一列,无论它是否包含在主键中,ClickHouse 都会存储相同的标记,这些标记可以让你在列数据文件中快速找到相应内容。
颗粒的大小通过参数 index_granularity 和 index_granularity_bytes 控制,一般我们只会设置 index_granularity 参数,默认为 8192,亦即数据分片每隔 8192 行创建一个逻辑颗粒并标记一下主键值(索引)。颗粒的行数会在 [1, index_granularity] 区间范围内。
在文件系统中数据分片目录中的内容如下所示。
20200101_4577_4581_1 |
column_name.mrk:表中每一列都有一个mrk文件,用于存储主键值的标记以及其在数据文件中的偏移量 (offset) 。column_name.bin:表中每一列都有一个bin文件,用于存储压缩后的真实数据。primary.idx:索引文件,存储了所有的主键值标记。
在查询时,ClickHouse 会先从索引文件中选出符合条件的主键标记,然后到指定的 column_name.mrk 文件中获取数据文件的偏移量,最后从 column_name.bin 文件中加载指定偏移量范围的数据到内存,解压缩后做数据过滤并得到最终的查询结果。
数据索引
在数据存储一节我们粗略的介绍了一下主键索引,下面我们通过一个例子来看一下 ClickHouse 索引的具体实现。
假设我们以 (CounterID, Date) 作为主键,排序好的主键稀疏索引如下图所示。
Whole data: [-------------------------------------------------------------------------] |
对于下面这些查询条件,我们来看一下 ClickHouse 的检索行为。
CounterID in ('a', 'h'),此时ClickHouse会读取标记号在[0, 3)和[6, 8)区间内的数据。CounterID IN ('a', 'h') AND Date = 3,此时ClickHouse会读取标记号在[1, 3)和[7, 8)区间内的数据。Date = 3,此时ClickHouse会读取标记号在[1, 10]区间内的数据。
上面例子可以看出,使用索引通常会比全表扫描要更为高效。
ClickHouse 中使用的稀疏索引会引起额外的数据读取,当读取主键单个区间范围内的数据时,每个数据块至多会多读取 index_granularity * 2 行额外的数据。大多数情况下,稀疏索引是常驻在内存中的,因此它可以使你快速处理大量的行数据。另外,ClickHouse 并不要求主键的唯一性,所以你可以插入多条具有相同主键的行。
在 ClickHouse 中,并没有限制主键中列的数量,但是选择合适数量的主键对数据查询与存储都会有帮助。首先它可以改善主键索引的性能,使得查询更快;其次因为 ClickHouse 是以主键排序分片数据,而数据的一致性越高,其压缩性能越好,越有助于节约磁盘空间;另外如果主键过长,会对数据插入性能和内存消耗都有负面影响,因此可以根据实际情况选取最优的主键组合。
以上就是 ClickHouse 中 MergeTree 系列引擎数据分区,数据存储以及数据索引等功能的具体实现,了解这些内容,可以更好地帮助我们优化查询语句以提升查询效率。
Log 系列引擎
与 MergeTree 系列引擎不同,Log 系列引擎主要是为了小表写入的场景而开发的。该系列引擎主要包括三类,分别为 StripeLog,Log 和 TinyLog,它们具有如下共同属性。
数据存储在磁盘上。
写入时数据会被追加在文件末尾。
支持并发访问锁,在执行
INSERTs操作时,表会加锁,其它的读写请求会一直等到表解锁后才能执行。不支持
Mutations操作。不支持索引,因此在范围查询时效率不高。
它们也有一些显著的差异,Log 引擎会将表中的每一列存储为不同的文件,而 StripeLog 引擎则将所有的数据存储在一个文件中。因此 StripeLog 引擎在操作系统中使用更少的文件描述符,但是 Log 引擎提供了更好的数据读取性能。TinyLog 引擎是该系列中最简单的引擎,它提供了最少的功能和最低的性能,你可以在简单的低负载场景下使用它。
分布式表引擎
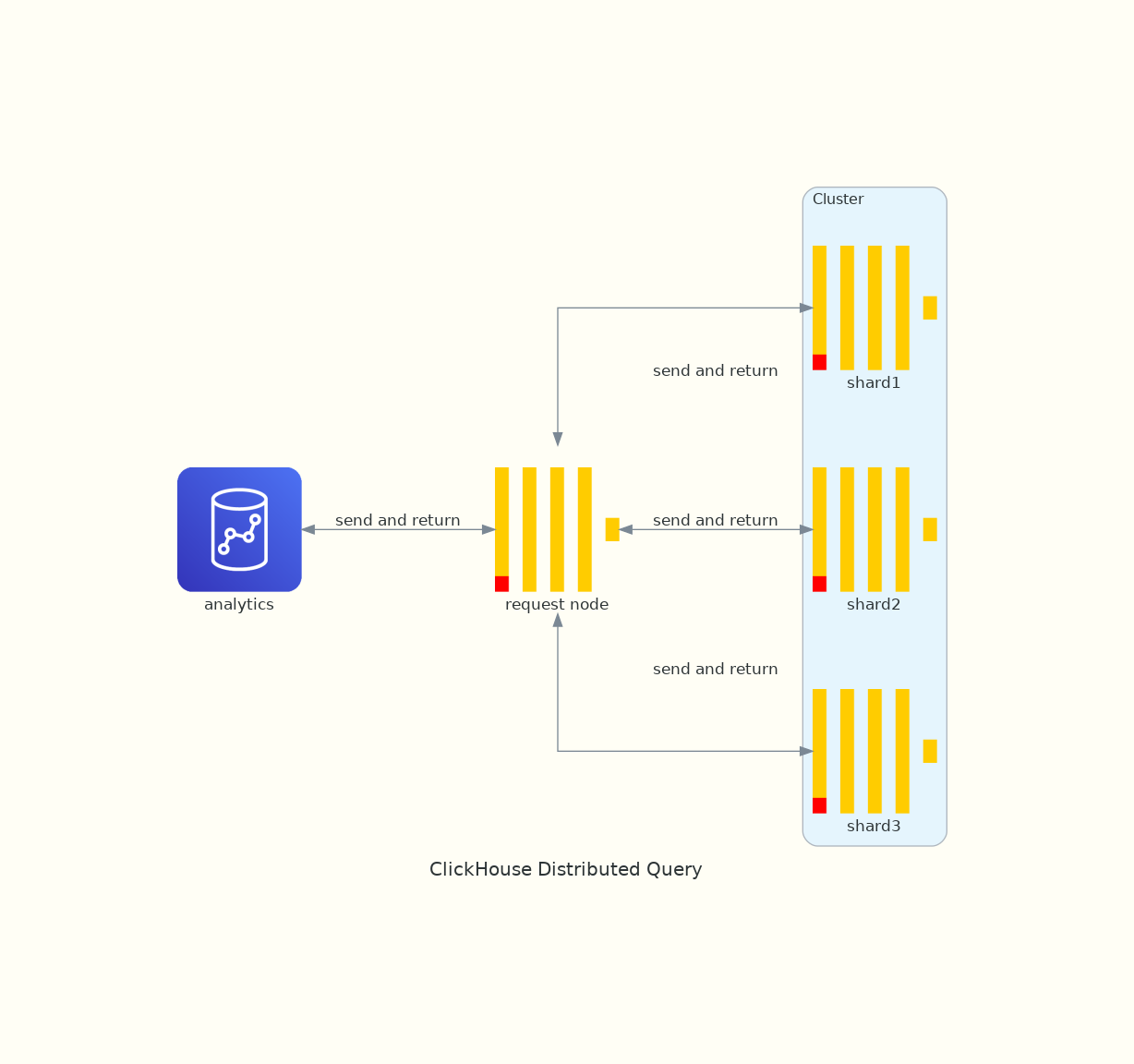
与前面介绍过的引擎不同,Distributed 表引擎本身并不存储数据,它主要用于分布式数据读取。使用该引擎可以在多个 ClickHouse 节点进行分布式查询并聚合多个节点的查询结果,查询操作自动在各节点间的本地表上并行执行,不需要人为干预,另外,如果本地表有索引,则会使用索引来加速查询进程。
Distributed 引擎建表语句如下所示。
Distributed(cluster_name, database, table[, sharding_key]) |
其中 cluster_name 对应于 ClickHouse 配置文件中 remote_servers 配置项的集群名称。database 表示本地数据库名称,table 为本地表名称,sharding_key 是可选项,在数据插入时会被用到。
需要注意,分布式表的表结构应该与本地表 table 的表结构相同,一般会使用 CREATE TABLE distributed_table as table ENGINE=Distributed(...) 语句来创建分布式表。
当使用分布式表进行查询时,它会从 cluster_name 集群中所有节点的 database.table 表中读取数据,然后将所有节点的查询结果聚合并返回。其中远程的节点不仅用于数据读取,它们还会尽可能地对数据进行部分处理。例如对于使用 GROUP BY 子句的分布式查询,数据首先会在各个远程节点进行聚合,之后返回聚合的中间状态给请求的节点,然后再在请求的节点进一步地聚合数据,这样可以减少请求节点的内存占用并提升查询的性能。
在集群的配置中,每个分片 (shard) 可能会有多个副本 (replica),而在分布式查询时,我们只需选取其中的一个即可(默认副本间的数据是一致的),副本的选择是由 ClickHouse 根据负载均衡策略自动完成的,默认为 Random 表示随机选择一个可用副本,还可以使用 In Order 策略表示按顺序选择等等。
在分布式查询时,如果请求节点未建立与分片所在节点的网络连接,会在短时间内进行重连,如果重连失败,则会选择分片的下一个副本,以此类推。如果与分片的所有副本连接尝试都失败,则会用相同的方式再重复几次,这种机制有利于系统可用性,但并不保证完全容错,比如虽然远程节能够接受连接,但其无法正常工作或网络状况不佳,也会导致查询失败。
需要注意的是,只要有一个分片所在节点无法连接成功或查询失败,那么整个分布式查询就会失败。
在创建分布式表时,除了从配置文件中查询集群的信息以外,还可以通过系统表 system.clusters 来进行查询。当新添加或删除了集群配置时,也可以查询该表以验证修改是否生效。
通过分布式引擎就可以像使用本地表一样使用集群,但是,集群不是自动扩展的,如果要添加新节点,必须修改 ClickHouse 的配置文件。另外,最好给集群中的所有 ClickHouse 节点都添加相同的集群配置,这样就可以从任一节点使用分布式表进行查询了。
如果你每次要向不确定的一组分片或副本发送查询,则不适合创建分布式表,而应该使用 remote 表函数 remote('addresses_expr', db, table[, 'user'[, 'password']]) 来完成查询,其中 addresses_expr 可以是单个节点地址也可以是用逗号分隔的多个节点地址,其查询效果与分布式表类似,只不过远程节点的地址是动态变化的。
分布式表一般只用于查询,不建议用来写数据,在上面的集群配置中已经介绍过原因。
物化视图
在介绍物化视图之前,我们先了解一下视图的概念。普通的视图可以理解为是一个保存好的查询,当从视图读取数据时,这个保存的查询(视图)将被作为 FROM 子句的一个子查询来执行。最重要的一点是普通的视图并不存储数据。
物化视图与普通的视图类似,不同之处在于它会存储由 SELECT 查询转换后的结果数据。物化视图的创建方式如下所示。
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] AS SELECT ... |
其中 TO [db].[table] 参数表示导入物化视图的数据的存储位置,此时物化视图将会被作为一个媒介,来将 SELECT 查询的数据导入到另一个表中,而如果不使用该参数,那么必须指定 ENGINE 参数,表示直接将物化视图作为一张表使用。
物化视图的实现原理如下:当向 SELECT 查询指定的表中插入数据时,插入的数据会被 SELECT 查询所转换并插入到物化视图中。ClickHouse 中的物化视图更像一个插入操作的触发器,只有新插入的数据才会执行 SELECT 查询中的操作并插入到物化视图中,已有数据的任何变动(修改,删除等)都不会对物化视图产生影响。如果我们同时想将已有的数据聚合到物化视图中,那么只有通过 INSERT ... SELECT ... 操作来完成了。
创建物化视图的 SELECT 语句中可以包含 GROUP BY,ORDER BY 或者 LIMIT 等子句,但要注意的是这些转换操作是在每个插入的数据块上独立执行的。例如,如果使用了 GROUP BY 子句,数据会在插入物化视图的过程中聚合,但仅仅是在单个插入的数据块上执行了聚合操作,后续插入的数据并不会进一步地汇总,在执行 SELECT 查询时需要注意。
借助物化视图,我们可以更方便地将多个表的数据聚合到一起而无需使用 JOIN 操作。示例如下所示。
假设我们有两张表,分别为曝光表 (
view) 和点击表 (click)。现在我们要统计每天各个交叉维度的点击率,使用JOIN操作可以解决该问题,但这种方式的资源消耗是巨大的。为了使得查询更加方便,我们先创建好一张聚合表,然后创建两个物化视图分别将曝光表和点击表的数据导入到聚合表中。如下所示:
-- 建表
CREATE TABLE ctr
(
date Date,
dimension String,
view UInt64,
click UInt64
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMMDD(date)
ORDER BY (date, dimension)
SETTINGS index_granularity = 8192
-- 创建 view 物化视图
CREATE MATERIALIZED VIEW view_mv TO ctr
AS
SELECT
date,
dimension,
count() AS view,
toUInt64OrZero('0') AS click
FROM view
GROUP BY date, dimension
-- 创建 click 物化视图
CREATE MATERIALIZED VIEW click_mv TO ctr
AS
SELECT
date,
dimension,
toUInt64OrZero('0') AS view,
count() AS click
FROM click
GROUP BY date, dimension接着我们就可以使用聚合表来完成数据查询了,这种方式的查询性能无疑会更高。
SELECT date, dimension, ROUND(SUM(click)/SUM(view), 2) AS ctr FROM ctr GROUP BY date, dimension
当我们要对物化视图后接的表进行修改时,应该先分离物化视图 (DETACH),修改完表之后再重新挂载该视图 (ATTACH)。当要修改物化视图时,最好的办法就是删除重建 (DROP TABLE)。需要注意的是在修改的过程中,如果 SELECT 查询中指定的表还在插入数据,修改完成后要将这部分数据重新导入到物化视图中。
Buffer 表引擎
Buffer 表会先将数据缓存到 RAM 中,然后再周期性地把缓存的数据刷新到另外一个普通表中。建表的语法如下所示。
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes) |
其中,database.table 表示要刷新数据的表。num_layers 为并行的层数,在物理上表示 num_layers 个独立的缓冲区 (buffers),推荐的值为 16。min_time,max_time,min_rows,max_rows,min_bytes 以及 max_bytes 都表示从缓冲区刷新数据的条件。
当满足所有 min* 条件或至少一个 max* 条件时,则会将数据从缓冲区刷新到目标表中。min_time 和 max_time 表示从数据第一次写入缓冲区时起以秒为单位的时间条件。min_rows 和 max_rows 表示缓冲区中的行数条件。min_bytes 和 max_bytes 表示缓冲区中的字节数条件。
在写入 Buffer 表时,数据会从 num_layers 个缓冲区中随机插入,每个缓冲区的数据刷新条件是分别计算的。另外,如果插入数据量足够多(大于 max_rows 或 max_bytes),那么插入操作会绕过缓冲区而直接将数据写入目标表。
示例:
CREATE TABLE merge.hits_buffer AS merge.hits ENGINE = Buffer(merge, hits, 16, 10, 100, 10000, 1000000, 10000000, 100000000) |
上述列子创建了一个 Buffer 引擎表 hits_buffer,它的表结构与 hits 表相同。写入此表时,数据会先缓冲到 RAM 中,然后再刷新到 hits 表。hits_buffer 表创建了 16 个缓冲区。如果从数据写入开始已经过了 100 秒,或者已经写入了 100 万行,或者写入的数据量达到了 100MB,则会刷新缓冲区里的数据到目标表。如果从数据写入开始已经过了 10 秒并且已经写入了 10000 行和 10MB 大小的数据量,那么也会刷新缓冲区里的数据到目标表。
当服务器停止时,或者使用 DROP TABLE 或 DETACH TABLE 语句操作 Buffer 表时,数据也会从缓冲区刷新到目标表。
使用 Buffer 表执行 SELECT 操作时,将会同时从 Buffer 表和目标表获取数据。但是建议只使用 Buffer 表进行数据写入,而从目标表执行真正的数据读取操作,这样做是为了提升查询效率。
如果需要为目标表和 Buffer 表运行 ALTER,建议先删除 Buffer 表,然后为目标表运行 ALTER,最后再次创建 Buffer 表。
Buffer 表适用于单位时间内有大量的 INSERTs 插入请求的情况,因为对于 MergeTree 系列的表,高频率的插入,会导致其后台数据的 Merge 变慢,从而影响性能甚至引发 too many parts exception 异常,而在 MergeTree 表前使用 Buffer 表可以在很大程度上缓解这一问题。另外,需要注意的是,即使使用了 Buffer 表,在 INSERT 时也应尽量采用大批量的形式进行数据插入以提升写入性能。
系统表
系统表是 ClickHouse 服务在启动时自动创建的表,大部分系统表都会将数据存储在内存里。
ClickHouse 的系统表提供以下信息:节点的状态,节点执行插入和查询的进程列表以及节点的环境变量等。系统表位于 system 数据库,只能用于数据读取而不能修改和删除。
下面介绍一些常用的系统表,在我们修改配置或查询问题时可能会用到。
system.clusters:该表包含了ClickHouse配置文件中的集群信息,包括集群名称以及集群状态等。通过该表,我们可以实时查询集群配置的修改是否生效。system.columns:该表包含了ClickHouse所有表的列信息,包括列名称以及列类型等。通过该表,我们可以查询该ClickHouse节点上所有表的结构信息以及列数。system.dictionaries:该表包含了ClickHouse所有外部字典的信息,包括字典名称以及字典的加载状态等。通过该表,我们可以查看字典的内容是否已经于近期更新。system.metrics:该表包含了ClickHouse实时的指标信息,包括正在执行的查询数量等。通过该表,我们可以大致了解ClickHouse的实时状态。system.asynchronous_metrics:该表包含了ClickHouse异步的指标信息,它们会在后台定期地计算,包括内存的使用信息等。通过该表,我们可以大致了解ClickHouse在过去一段时间内的状态。system.mutations:该表包含了MergeTree表的Mutations操作信息,包括具体的Mutations命令以及Mutations操作的进度等。通过该表,我们可以确定Mutations操作是否完成。system.parts:该表包含了MergeTree表中的所有分区以及分片信息,包括分区、分片名称以及分片的状态等。通过该表,我们可以查看数据分片的合并情况。system.processes:该表包含了ClickHouse节点当前执行的所有插入以及查询语句,SHOW PROCESSLIST命令就是通过查询该表实现。通过该表,我们可以查询内存占用最大的查询语句的query_id或分布式查询的initial_query_id,然后使用KILL QUERY $id命令来结束该语句的执行。system.replicas:该表包含了ClickHouse所有复制表的信息,包括复制表的名称以及其与ZooKeeper的连接状态等信息。通过该表,我们可以查看复制表的元数据在ZooKeeper中的路径,以供问题排查使用。system.settings:该表包含了ClickHouse当前用户的一些配置信息,包括配置的名称以及值等。通过该表,我们可以实时查询用户配置的修改是否生效。system.users:该表包含了ClickHouse的所有用户信息,包括用户名称以及授权访问的IP等。通过该表,我们可以查询某个用户的访问限制。system.zookeeper:如果ClickHouse配置了ZooKeeper,该表会存储ZooKeeper集群的信息。在查询时必须在WHERE子句中指定path过滤条件,会读取ZooKeeper中指定path下的所有节点信息,包括节点名称,节点的值以及节点的数据长度等。通过该表,我们可以查询ZooKeeper所有节点的信息。但一般而言,使用第三方图形化工具查看ZooKeeper节点会更加方便和直观。
其它的系统表可以按需查询,具体可参见官方文档,这里就不再过多介绍。
ClickHouse 常用操作
建表
建表语法如下。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine其中
name表示列名,type表示列的类型。可以通过表达式的形式给某一列指定默认值,该默认值可以是常量或列的任意表达式。当创建或更改表结构时,
ClickHouse将会运行检查,确保默认值的表达式不会包含循环依赖,对于INSERT语句,ClickHouse仅检查该默认值的表达式是否可以解析,亦即可以从表达式中计算出相应的值。通常有以下三种方式来指定列的默认值。DEFAULT expr:正常表达式,如果插入语句中没有指定该列的值,那么它将通过计算相应表达式的值来填充该列。如URLDomain String DEFAULT domain(URL)会使用URL的域名来填充URLDomain列。MATERIALIZED expr:物化表达式,使用物化表达式的列不能包含在INSERT语句中,因为它总是被计算出来并存储到表中的。另外,在使用SELECT *查询时,此列也不会显示。ALIAS expr:别名表达式,与物化表达式相似,它的值也不能通过INSERT写入,同时在使用SELECT *查询时,此列也不会显示。但不同之处在于该列并不存储值,查询该列时总是会重新计算一次表达式并返回相应的结果。
在默认情况下,对于使用
MergeTree系列引擎的表,ClickHouse使用lz4压缩方法来对数据进行压缩,但你可以通过指定compression_codec来修改每一列的压缩方法。TTL子句可定义列的存储时间,只能为使用MergeTree系列引擎的表指定。ENGINE子句上面已经介绍过,可根据需求使用不同的表引擎。除了以上建表方式外,当我们需要创建与现有表结构相同的表时,可以使用
CREATE TABLE ... AS ...方法来简化创建流程。CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
该方法一般在创建分布式表时较为常用。
修改表结构
表结构修改的语法如下所示。
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ... |
ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [codec] [AFTER name_after]该语句可以在表中指定列的后面新增一列,新增的列不会对已有数据产生影响,执行完成后磁盘上不会出现该列的数据,查询时如果数据为空就会使用默认值进行填充。只有当数据分片完成一次合并后,该列的文件才会出现在磁盘上。DROP COLUMN [IF EXISTS] name该语句可以删除表中的一列,由于删除的是列的整个文件,该操作几乎是立即完成的。CLEAR COLUMN [IF EXISTS] name IN PARTITION partition_name该语句会重置表中指定分区的列值为默认值。MODIFY COLUMN [IF EXISTS] name [type] [default_expr] [TTL]该语句会修改指定列的属性。当修改type时,列值会被转换为对应的数据类型。
操作表数据
删除指定分区,语法如下所示。
ALTER TABLE table_name DROP PARTITION partition_expr
该操作会将分区标记为非激活状态,并在大约
10分钟左右将该分区数据完全删除。分离指定分区,语法如下所示。
ALTER TABLE table_name DETACH PARTITION partition_expr
该操作会将指定分区的数据移动到
detached目录。挂载指定分区/分片,语法如下所示。
ALTER TABLE table_name ATTACH PARTITION|PART partition_expr
-- example
ALTER TABLE visits ATTACH PARTITION 202001;
ALTER TABLE visits ATTACH PART 202001_2_2_0;该操作会将
detached目录下挂载数据到数据表中,可以是整个分区的数据或者是单独分片的数据。从其它表复制并挂载指定分区,语法如下所示。
ALTER TABLE table2 ATTACH PARTITION partition_expr FROM table1
该操作将
table1表中指定分区的数据复制到table2表中的已有分区,注意table1表中的数据不会被删除。为了保证操作能成功运行,2张表必须具有相同的表结构和分区键。将分区数据移动到其它表,语法如下所示。
ALTER TABLE table_source MOVE PARTITION partition_expr TO TABLE table_dest
该操作将
table_source表中指定分区的数据移动到table_dest表,并删除table_source表的数据。同理,2张表必须具有相同的表结构和分区键。从其它表复制并替换指定分区,语法如下所示。
ALTER TABLE table2 REPLACE PARTITION partition_expr FROM table1
该操作将
table1表中指定分区的数据复制到table2表,并替换table2表中的已有分区。注意table1表中的数据不会被删除。同理,2张表必须具有相同的表结构和分区键。删除符合指定条件的数据,语法如下所示。
ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr
该操作是一项繁重的操作,并非为频繁使用而设计。它是异步执行的,可能需要等待一段时间后,符合条件的数据才会删除完成。
修改符合指定条件的数据,语法如下所示。
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr
同删除操作一样,该操作也非为频繁使用而设计。它也是异步执行的,需要一段时间来完成操作。
对表中数据进行
DELETE和UPDATE的ALTER操作是通过一种称为Mutations的机制实现的。对于使用MergeTree系列引擎的表,Mutations通过重写整个数据块来实现,这是一项重量级的操作。在数据重写期间执行SELECT查询能看到已经完成Mutations的数据以及还没有被Mutations覆盖的数据。Mutations不会阻塞数据的插入,而且在Mutations开始执行之后插入的数据不会参与Mutations操作。Mutations操作在提交之后会立即返回,它会在后台异步执行,要跟踪Mutations的进度,可以使用系统表system.mutations进行查询。已成功提交的Mutations操作不可撤回,在ClickHouse重启后仍会继续执行。
分离/挂载表
分离表,语法如下所示。
DETACH TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]
该操作会从
ClickHouse节点删除指定表的信息,DETACH后ClickHouse将感知不到该表的存在。但是该操作并不会删除表的数据和元数据,在ClickHouse节点下次启动时将会再次挂载该表,并知晓该表的存在。当然,我们也可以通过ATTACH操作来挂载该表。一般在我们需要对表的数据存储位置进行调整而且不想重启
ClickHouse服务时会使用DETACH操作。挂载表,语法如下所示。
ATTACH TABLE [IF NOT EXISTS] [db.]name [ON CLUSTER cluster]
ATTACH操作与CREATE操作的作用基本相同,不同点在于该操作并不在磁盘上创建数据文件,它会假定数据已经存储于合适的位置。ATTACH操作只是将指定表的信息添加到ClickHouse节点,使ClickHouse知晓该表的存在。ClickHouse的元数据文件夹存储的就是一系列包含ATTACH操作的SQL文件,在ClickHouse节点启动时会使用这些元数据文件来加载表的结构以及数据。需要注意在分离表之前,应该先停止数据导入操作。
分布式批处理
在默认情况下,CREATE,DROP 以及 ALTER 等操作只会在当前 ClickHouse 节点上执行,而这些操作一般都会以集群为单位去执行的,为了避免去其它节点手动操作的烦恼,我们可以使用 ON CLUSTER 子句来使得整个集群同步修改。语法如下所示。
CREATE TABLE IF NOT EXISTS all_hits ON CLUSTER cluster_name AS hits ENGINE = Distributed(cluster_name, default, hits) |
上述语句会在 cluster_name 集群的每个节点上都创建分布式表 all_hits。为了确保这些集群操作正确执行,每个 ClickHouse 节点必须具有相同的集群配置文件。
GLOBAL IN 操作
使用带有子查询的 IN 操作时(即 IN Subquery),ClickHouse 提供了两种选项,分别为 IN 和 GLOBAL IN,它们在分布式查询下会有不同的表现。
让我们看一个例子,假设集群中每个节点都有一个本地表 local_table,另外还有一个分布式表 distributed_table。当使用分布式表进行查询时,该查询会被发送到所有的远程节点,并在它们的本地表上执行真正的查询操作。例如对于以下查询:
SELECT uniq(UserID) FROM distributed_table |
将会以如下形式发送到所有的远程节点:
SELECT uniq(UserID) FROM local_table |
远程节点执行完毕后会将结果返回给请求节点并在请求节点上进一步聚合,然后将最终的结果发送给终端用户。
当我们使用带有 IN 操作的分布式查询时,示例语句如下所示:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34) |
该查询将会以如下形式发送到所有远程节点:
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34) |
也就是说,IN 子句中的数据集会从每个节点单独获取,仅需访问每个节点的本地表。如果你已经将数据分散到各个节点,并且确保单个 UserID 对应的数据都落在同一个服务器节点上,那么这种查询方式将会是准确的也是最佳的查询方式,否则查询结果将会出错。更为通用的方法是在 IN 的子查询中使用分布式表来聚合所有节点的数据,示例语句如下所示:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34) |
该查询将会以如下形式发送到所有远程节点:
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34) |
另外,由于在子查询中使用了分布式表,该子查询又会以如下形式再次发送到所有远程节点:
SELECT UserID FROM local_table WHERE CounterID = 34 |
假设一个 ClickHouse 集群有 100 个节点,那么执行上述查询操作将会需要执行 100*100=10000 个基础查询,这一般是不可接受的。在这种情况下,我们应该始终使用 GLOBAL IN 而非 IN。示例语句下所示:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID GLOBAL IN (SELECT UserID FROM distributed_table WHERE CounterID = 34) |
此时请求节点将会先单独执行子查询:
SELECT UserID FROM distributed_table WHERE CounterID = 34 |
然后将返回的结果放置于内存中的一个临时表中,接着整个查询将会以如下方式发送到所有远程节点:
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID GLOBAL IN _data1 |
这里 _data1 是指内存中的临时表,它会随查询一起发送给远程的节点。此时上述查询操作只需进行 100+100=200 个基础查询,查询量大大减少。
另外,JOIN 操作也具有同样的性质,在使用时需要注意。
数据导入/导出
从文件中导入数据,需要借助
clickhouse-client工具。cat data.csv | clickhouse-client ---query="INSERT INTO test FORMAT CSV"
将查询结果导出到文件,既可以直接使用
SQL语句也可以使用clickhouse-client工具。SELECT * FROM table INTO OUTFILE 'data.csv' FORMAT CSV
clickhouse-client --query "SELECT * from table" --format CSV > data.csv
KILL 操作
KILL QUERY,语法如下所示。KILL QUERY [ON CLUSTER cluster]
WHERE <where expression to SELECT FROM system.processes query>
[SYNC|ASYNC|TEST]
[FORMAT format]该操作会强制终止某个正在运行的查询/插入语句,它会根据
WHERE子句中的过滤条件去system.processes表中查询指定的QUERY并KILL掉。默认情况下,该操作是异步的,它不会等待
KILL的QUERY完全停止而是立即返回。如果使用同步方式,则该操作会等待所有QUERY停止并显示每个已停止QUERY的具体信息。示例:
-- Forcibly terminates all queries with the specified query_id:
KILL QUERY WHERE query_id='2-857d-4a57-9ee0-327da5d60a90'
-- Synchronously terminates all queries run by 'username':
KILL QUERY WHERE user='username' SYNC当某些查询语句的内存占用过高,而
ClickHouse没有主动将其KILL掉时,需要我们手动执行KILL操作。首先,我们要从system.processes表中查询内存占用过高的QUERY的query_id,然后确认是否有权限处理该QUERY,最后再将其KILL掉。在多数情况下,我们执行的一般为分布式查询,而分布式查询在每个
ClickHouse节点上的query_id都是不同的,无法统一执行KILL操作。此时我们可以使用其initial_query_id,它在每个ClickHouse节点上都是相同的,然后再利用ON CLUSTER子句将每个节点的查询都KILL掉。KILL QUERY ON CLUSTER cluster_name WHERE initial_query_id='2-857d-4a57-9ee0-327da5d60a90'
KILL MUTATION,语法如下所示。KILL MUTATION [ON CLUSTER cluster]
WHERE <where expression to SELECT FROM system.mutations query>
[TEST]
[FORMAT format]该操作会尝试取消并删除当前执行的
Mutations操作,它会根据WHERE子句中的过滤条件去system.mutations表中查询指定的Mutations并KILL掉。示例:
-- Cancel and remove all mutations of the single table:
KILL MUTATION WHERE database = 'default' AND table = 'table'
-- Cancel the specific mutation:
KILL MUTATION WHERE database = 'default' AND table = 'table' AND mutation_id = 'mutation_3.txt'当某些
Mutations操作被卡住而无法完成时,我们可以手动执行KILL操作。
ARRAY JOIN 操作
对于包含数组列的表来说,我们在查询时往往希望将数组中的元素展开,ARRAY JOIN 子句可帮我们实现这一目标。它会生成一个新表,该表包含一列,对应于原表中的数组列,该列的值为所有展开的数组元素的值,而其它列的值将会被重复显示。
ARRAY JOIN 子句的语法如下所示:
SELECT <expr_list> |
在一般情况下,使用 ARRAY JOIN,空数组所在的行将不会包含在最终的结果中,而使用 LEFT ARRAY JOIN 时,最终的结果会包含空数组所在的行。
需要注意在一个 SELECT 查询中,你只能使用一个 ARRAY JOIN 子句。
下面的例子展示了 ARRAY JOIN 的用法。让我们先创建一个包含 Array 列的表并插入值。
CREATE TABLE arrays_test |
┌─s───────────┬─arr─────┐ |
使用 ARRAY JOIN 来进行查询:
SELECT s, arr |
┌─s─────┬─arr─┐ |
使用 LEFT ARRAY JOIN 来查询:
SELECT s, arr |
┌─s───────────┬─arr─┐ |
另外我们还可以在 ARRAY JOIN 时使用 AS 子句为数组元素指定别名,方便与数组列本身进行区分。
条件函数
条件函数 if 用于控制条件分支,与大多数数据库系统不同,ClickHouse 会同时评估两个表达式。 if 语句语法如下所示。
SELECT if(cond, then, else) |
cond表示条件表达式,表达式的结果可以为0或非0。then表示满足cond条件时(非0)返回的值。else表示不满足cond条件时 (0) 返回的值。
示例如下:
SELECT * |
┌─left─┬─right─┐ |
SELECT |
┌─left─┬─right─┬─is_smaller──────────────────────────┐ |
如果单独的 if 语句不能满足你的需求,还可以使用 multiIf 语句,语法如下所示。
multiIf(cond_1, then_1, cond_2, then_2, ..., else) |
示例如下:
SELECT |
┌─left─┬─right─┬─result──────────┐ |
对于一些聚合函数,同样可以支持 if 操作,通过在聚合函数后添加 If 来实现,如 sumIf(column, cond),countIf(cond),avgIf(x, cond) 等。加了 If 之后的聚合函数需要接收一个额外的条件表达式,此时聚合函数只会处理那些满足条件的行数据。
使用了条件聚合函数后,你可以在一次查询中计算满足多个条件的聚合结果,而无需使用子查询和 JOIN 操作,大大简化了查询的复杂度。
其它操作
近似计算:比如在查询
UV时可使用uniq()方法而非count(distinct ...)方法。其中uniq()即为近似计算方法,执行近似计算时,ClickHouse会先在部分数据上执行查询,然后获得一个全局的近似结果。使用该操作会有损数据精度,但整体的数据量级基本一致。另外,在执行近似计算时,从磁盘读取的数据量将会大规模减少,查询的速度也会大幅度提升,因此,如果可行的话,应尽量使用近似计算来完成查询。表数据相互导入:对于结构不同的表,可以使用
INSERT ... SELECT ...语句从一个表导入数据到另外一个表,对于结构相同的表,除了上述方法外,还可以采用ALTER TABLE ... ATTACH PARTITION ... FROM ...语句来完成数据导入。
ClickHouse 访问接口
ClickHouse 提供了两种网络访问接口,分别为 HTTP 接口和 TCP 原生接口。
Client 访问
ClickHouse 提供了一个原生命令行客户端工具 clickhouse-client 来与 ClickHouse 进行交互,该客户端支持命令行参数以及配置文件。
clickhouse-client 使用 TCP 原生接口来访问 ClickHouse,你可以选择交互式模式或非交互式模式来使用它。
在交互模式下,你将进入一个命令行,可以在该命令行中输入查询语句,然后按下 Enter 键执行查询并返回结果。如果没有指定 --multiline(-m) 参数,若想输入多行语句,可以在换行前输入一个反斜杠 \,如果指定了 --multiline(-m) 参数,则默认为多行输入,查询语句需要以分号结尾才可按 Enter 键执行。若要退出客户端可以使用 Ctrl+C 或者输入 exit 等命令。
当一个查询执行时,客户端会显示查询的进度,默认每秒更新 10 次,同时还会显示格式化后的查询语句以及指定格式的输出结果等信息。
在非交互模式下,需要指定 --query(-q) 参数,或者将数据发送到标准输入 (stdin),或者两者同时使用。当两者同时使用时,发送给 ClickHouse 的真实请求是 query 参数、换行符以及标准输入中的数据的串联组合,这对于大规模的数据插入操作非常方便。
示例如下所示:
echo -ne "1, 'some text', '2016-08-14 00:00:00'\n2, 'some more text', '2016-08-14 00:00:01'" | clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV"; |
默认情况下,使用非交互模式只能处理一个查询,如果想同时执行多个查询,可以使用 --multiquery(-n) 参数,该参数对除 INSERT 之外的所有查询操作都生效,但这种情况下所有查询的输出都是连续的,没有额外的分割符。当然你也可以对每个查询运行 clickhouse-client,但要注意启动 clickhouse-client 程序可能需要数十毫秒,需要你根据实际情况来权衡使用。
另外,你可以通过命令行或配置文件的方式向 clickhouse-client 传递参数,具体的参数信息可通过 clickhouse-client --help 命令来查看。
HTTP 访问
HTTP 接口可以让你通过任何平台和编程语言来访问 ClickHouse。相对而言,HTTP 接口比 TCP 原生接口更为局限,但是却有更好的兼容性。
默认情况下,ClickHouse 会在 8123 端口监听 HTTP 请求。如果你发送一个不带参数的 GET 请求,它会返回一个 OK 字符串,你可以将它用在 ClickHouse 的健康检查脚本中。
curl 'http://localhost:8123/' |
在使用 curl 等工具访问 ClickHouse 的 HTTP 接口时,可以通过 URL 中的 query 参数发送请求,或者发送 POST 请求,或者将查询的开头部分放在 query 参数中,而将其它部分放在 POST 中。URL 的大小会被限制在 16KB,在发送大规模的查询请求时需要注意这一点。
如果请求成功,将会收到 200 响应状态码和查询的结果,如果发生了某个异常,将会收到 500 响应状态码和异常描述信息。
当使用 GET 方法请求时,readonly 参数会被自动设置,也就是说若要作修改数据的查询,只能通过 POST 请求来完成。
使用 curl 请求 ClickHouse 的示例如下所示:
作为 query 参数,需要对 URL 进行编码,如空格编码为`%20`。 |
其中 @- 参数用来通知 curl 从标准输入读取数据。
需要注意,在查询时如果一部分请求是通过 query 参数发送,而另外一部分请求通过 POST 发送,那么在两部分请求之间会插入换行符。因此下面的查询会报错。
echo 'ECT 1' | curl 'http://localhost:8123/?query=SEL' --data-binary @- |
INSERT 操作必须通过 POST 方法来插入数据。在这种情况下,你可以将查询的开头部分放在 query 参数中,然后用 POST 传递待插入的数据。示例如下所示。
发送 POST 请求。 |
如果 ClickHouse 设置了用户认证,可以通过以下方式来指定用户名和密码,如果都不设置,默认使用 default 用户名和空密码。
HTTP Basic Authentication. |
另外,你还可以通过 URL 参数来指定处理单个查询的任意设置,比如设置最大的内存使用,避免内存超限:http://localhost:8123?max_memory_usage=30000000000&query=',设置最大的查询时间,避免查询超时:http://localhost:8123?max_execution_time=10&query=,更多设置可以参见用户 profile 相关配置项。
除了使用 curl 命令,你还可以使用一些第三方开源库来访问 ClickHouse,它们大多使用 HTTP 接口与 ClickHouse 进行交互。相对而言,curl 命令适用于在没有安装 clickhouse-client 的命令行下执行查询操作,常用于一些脚本;而第三方库则更适用于线上业务使用,如数据插入业务以及 OLAP 查询业务等,它们提供了更好的封装和更易用的接口,使用起来会更加方便。
ClickHouse 版本升级
一般在 ClickHouse 修复了重大 BUG 或有重大更新时,我们会选择对当前使用的 ClickHouse 版本进行升级。注意,如果当前使用版本与最新版本之间间隔久远,一定要先在测试节点进行测试,验证主要功能(包括且不限于分布式表、复制表、物化视图以及字典等功能)都正常后,再继续其它节点的升级过程。
ClickHouse 的升级过程很简单,按如下流程操作即可。
sudo yum update |
ClickHouse 升级的难点在于如何在升级过程中保证线上业务的正常运行,这里既包括数据导入业务以及数据查询业务。因为在升级的过程中要涉及 ClickHouse 服务重启,所以必然有部分查询业务是不可用的,为了尽可能保证服务的可用性,我们应该分别在每个节点单独执行升级操作(one by one)。
对于数据导入业务,我们需要保证该服务具有容错功能,也就是说当部分节点不可用时,数据依然可以正常导入到其它节点,而在节点恢复后还应继续向其导入数据。这样在 ClickHouse 升级期间,数据导入业务可以保证正常运行,而且数据总量也没有任何变化。
对于数据查询业务,如果是基于全部节点的分布式查询,那么在升级重启过程中,该服务必然不可用,暂无较为合适的方法来解决该问题。而对于一些重要的 OLAP 查询业务(数据量远小于原始数据),我们可以使用复制表来保证查询的可用性。根据分布式集群的配置,我们知道,当某个分片 (shard) 不可用时,ClickHouse 会尝试连接该分片的副本 (replica),那么只要我们保证副本之一所在节点是正常运行的,那么该查询服务就不会受到影响,也就是说在升级过程中,互为副本的两个 ClickHouse 节点不可同时进行重启操作。
基于上述方法,可以让我们平滑地完成整个 ClickHouse 集群的升级操作。
ClickHouse 作为 Grafana 数据源
ClickHouse 可以作为 Grafana 的数据源来使用,一来可以监控原始数据的量级是否正常,二来可以对某些统计指标做可视化展示。
首先需要使用如下命令给 Grafana 安装 ClickHouse 插件:
grafana-cli plugins install vertamedia-clickhouse-datasource |
接着需要为 Grafana 添加新的 ClickHouse 数据源,然后就可以添加 Grafana 面板进行数据展示了。
按照下图所示选取指定的数据源和时间列,然后点击 Go to Query 按钮即可显示数据曲线图。

如果想自定义查询内容,可以通过其原生 SQL 编辑器进行修改,如下图所示。
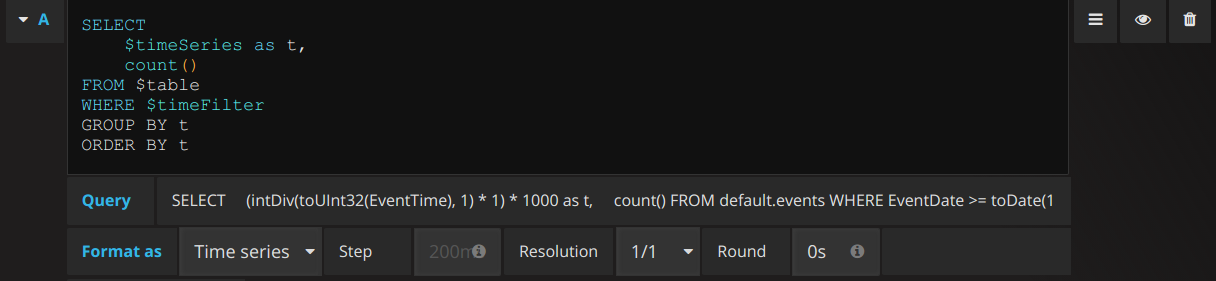
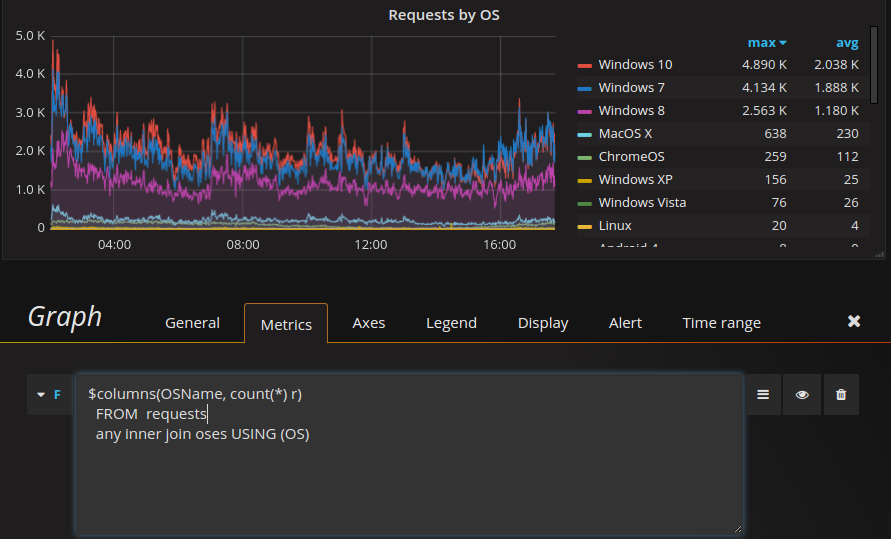
该 ClickHouse 插件还包括一些常用的函数来帮助我们简化查询,这些函数可以理解为 SQL 查询的模板,我们可以在原生的 SQL 编辑器中直接使用它们。比如我们想看一下各操作系统的用户访问量趋势,可以使用 $columns(key, value) 函数,其中 key 会被用作数据曲线的标签,value 表示相应标签的具体数量。使用示例如下所示。
$columns(OSName, count(*) c) |
上述函数会被转换为如下 SQL 语句并发送给 ClickHouse。
SELECT |
最终显示的结果如下图所示。
该插件的更多用法可参见其官方文档。
ClickHouse 监控
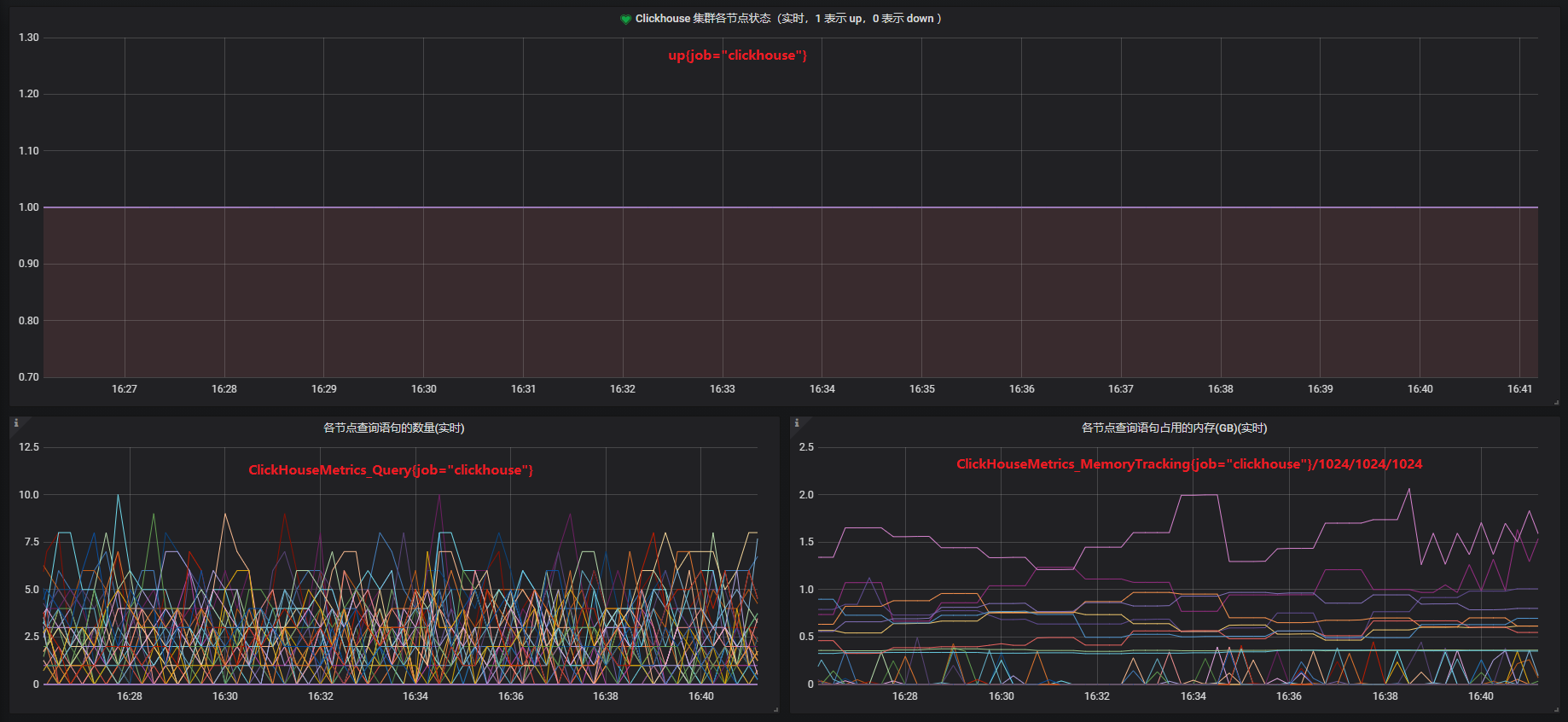
对 ClickHouse 进行监控是十分重要且必要的,它可以让我们快速发现 ClickHouse 服务的问题并及时解决。
我们可以通过一些系统表如 system.metrics 等大致了解 ClickHouse 的一些指标信息,但是表中的数据是非时序型的,不利于长期监控。因此 ClickHouse 提供了对外的指标接口,以供 Prometheus 等时序型数据库获取指标信息并加以存储,有了数据源后,我们就可以使用 Grafana 等工具对 ClickHouse 的各项指标进行监控了。
在使用 Prometheus 获取 ClickHouse 指标之前,我们需要先修改 ClickHouse 配置文件以启用指标获取接口,在配置文件一节已经介绍过相关内容,这里就不再赘述。然后我们要向 Prometheus 的配置文件中添加新的 job 以定期地获取 ClickHouse 指标信息,接着重启 Prometheus 服务使新配置生效。最后使用 Grafana 进行可视化监控,整体监控效果如下图所示。
另外,我们可以设置一些告警规则,以便及时了解 ClickHouse 的状态变化并进行相应的处理。
ClickHouse GUI 工具
DataGrip:商业的桌面GUI工具。Tabix:开源免费的WEB GUI工具。DBeaver:开源免费的桌面GUI工具。
ClickHouse 常见问题
重启
ClickHouse服务的时间会比较长:主要是由于该节点数据分片过多导致加载缓慢,耐心等待即可。数据插入报错
too many parts exception:主要是由于数据插入过于频繁,导致数据分片在后台merge缓慢,ClickHouse启动自我保护机制,拒绝数据继续插入。此时可尝试增大插入数据的batch_size(10 万) 并降低数据插入的频率(每秒1次)以缓解该问题。复制表变为只读:主要是由于
ClickHouse无法连接ZooKeeper集群或ZooKeeper上该复制表的元数据丢失导致的,此时新数据无法插入该表。若要解决该问题,首先要检查ZooKeeper的连接状况,如果连接失败,则需进一步检查网络状态以及ZooKeeper的状态,连接恢复后,复制表就可以继续插入数据了。如果连接正常而元数据丢失,此时可以将复制表转为非复制表然后再进行数据插入操作。执行
JOIN操作时内存超限:可能是由于JOIN前后的两个子查询中没有添加明确的过滤条件导致的,也有可能是由于JOIN的数据本身就很大,无法全部加载到内存。此时可以尝试增加过滤条件以减小数据量,或者适当修改配置文件中的内存限制,以装载更多的数据。
ClickHouse 问题排查方法
检查
ClickHouse运行状态,确保服务正常运行。检查
ClickHouse错误日志文件,寻找问题根源。检查系统日志文件 (
/var/log/messages) 中与ClickHouse相关的记录,查看是否是系统操作导致ClickHouse异常。对于未知问题或
BUG,可以到官方GitHub仓库的issue下寻求帮助,需提供完整的问题描述和错误日志信息。
参考资料
- 什么是 ClickHouse
- ClickHouse 特性
- ClickHouse 快速安装
- ClickHouse 配置文件
- ClickHouse 服务配置项
- ClickHouse 字典配置
- ClickHouse 字典函数
- ClickHouse 用户配置
- ClickHouse 用户参数设置
- ClickHouse 用户查询设置
- ClickHouse MergeTree 配置项
- ClickHouse 表引擎
- ClickHouse 分布式表
- ClickHouse 负载均衡配置
- ClickHouse remote 表函数
- ClickHouse 字典
- ClickHouse 系统表
- ClickHouse SQL 参考
- ClickHouse 访问接口
- ClickHouse 第三方库
- ClickHouse datasource for Grafana
- ClickHouse GUI 工具