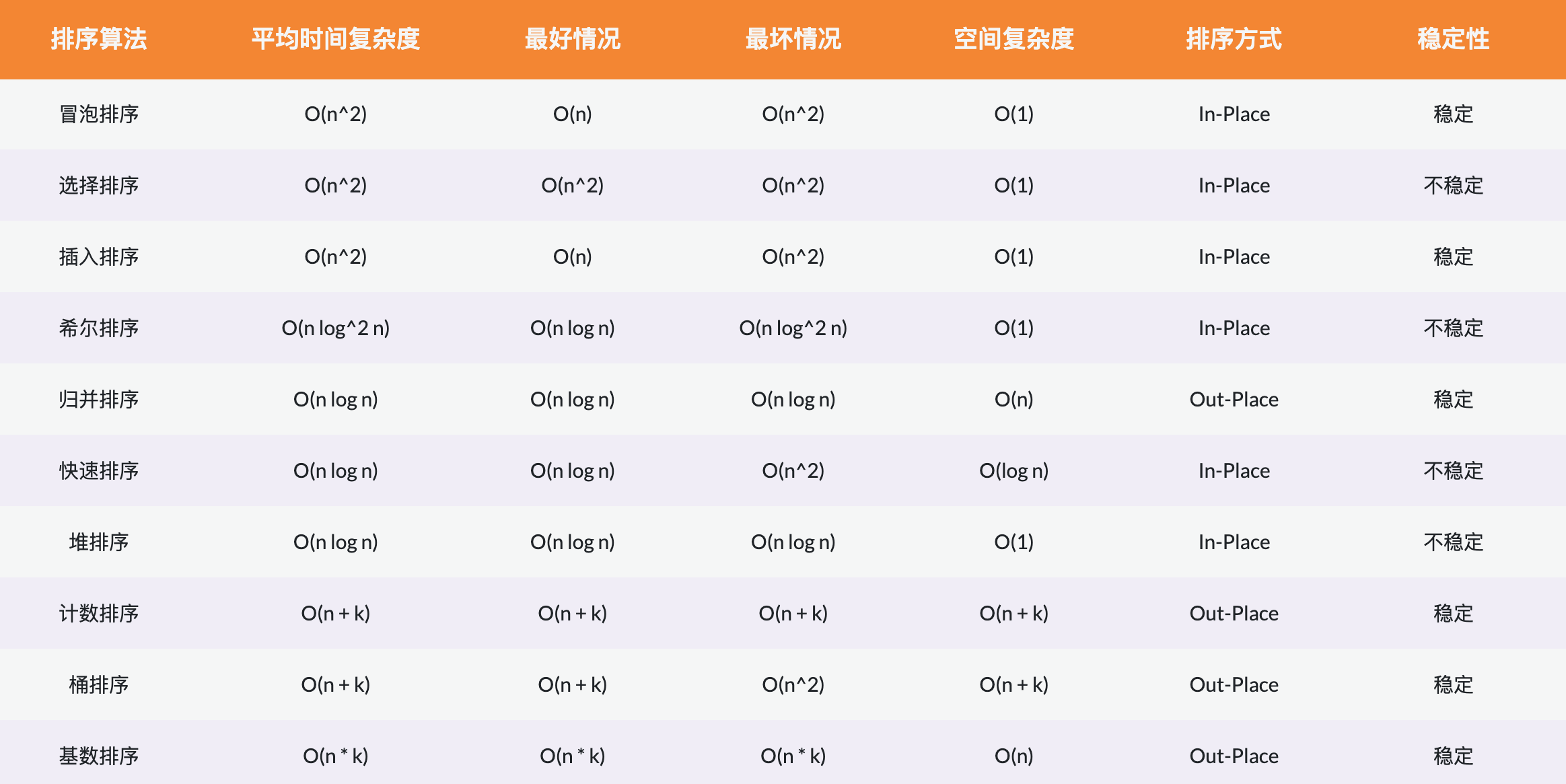
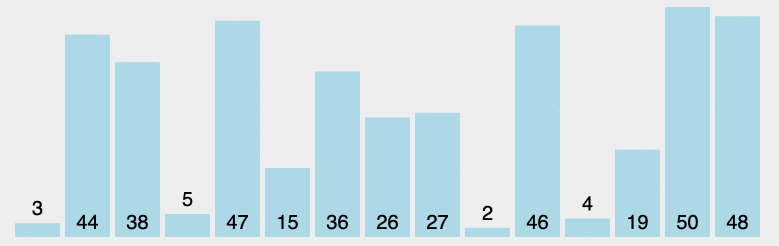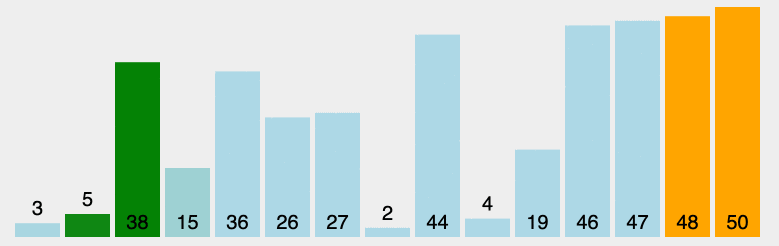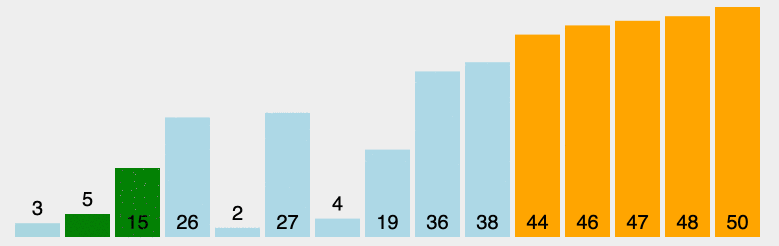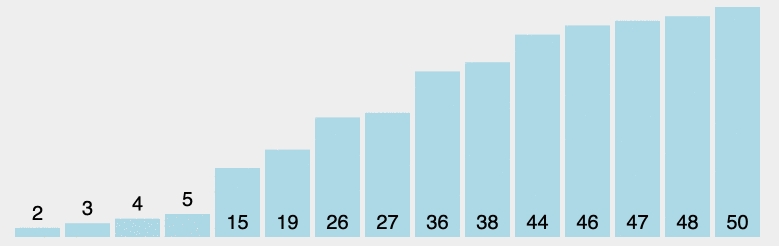
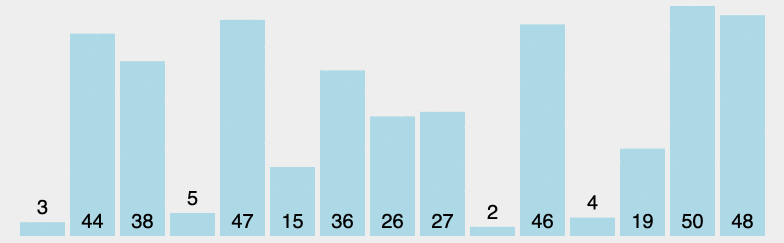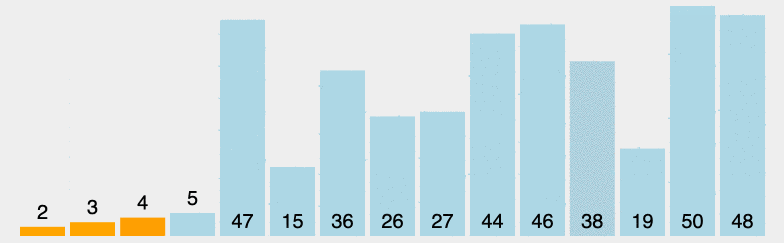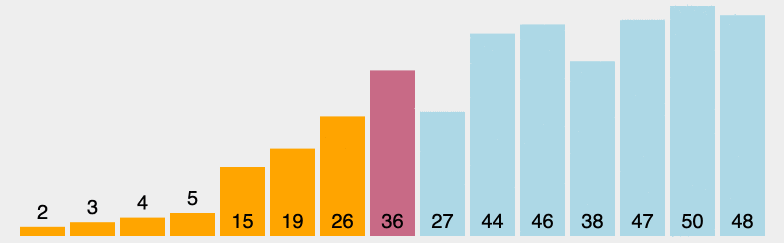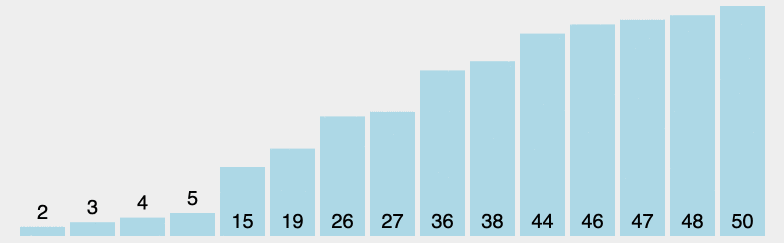
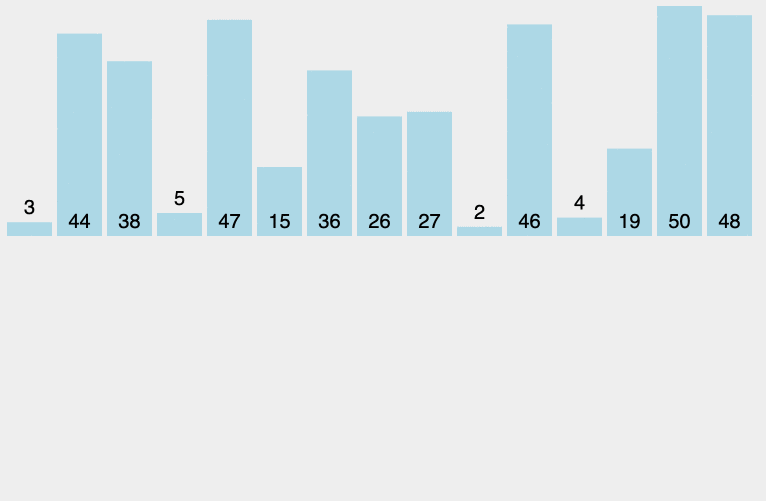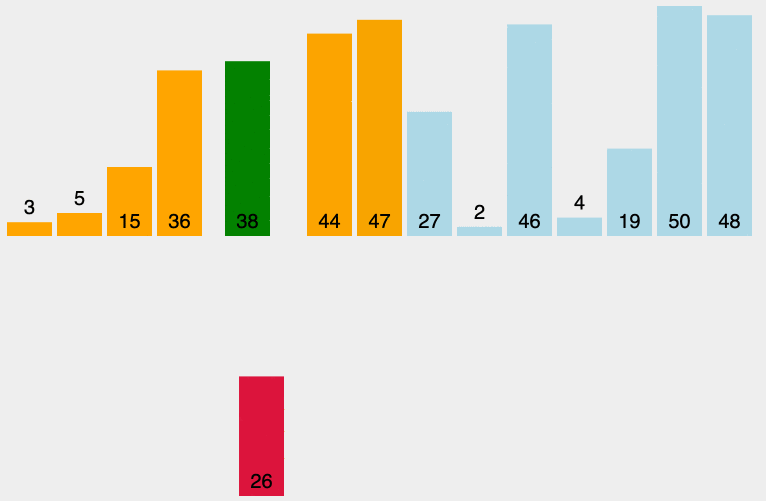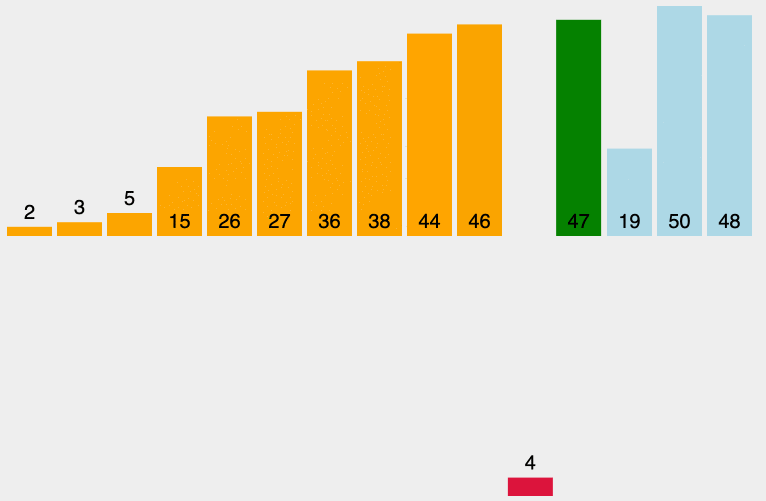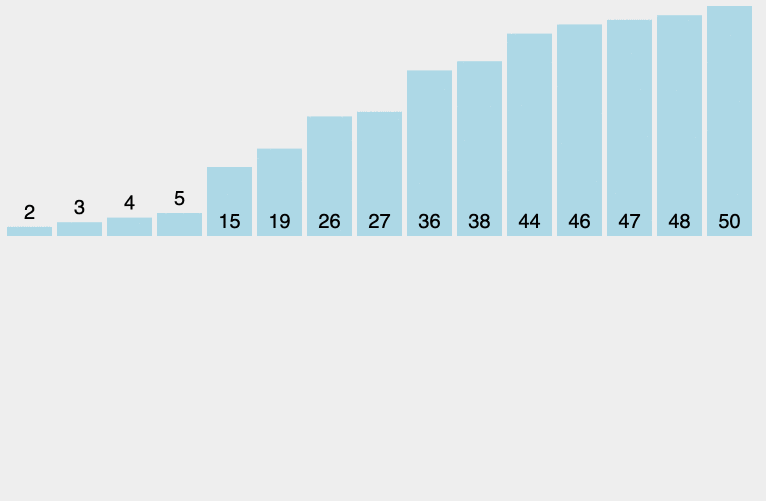
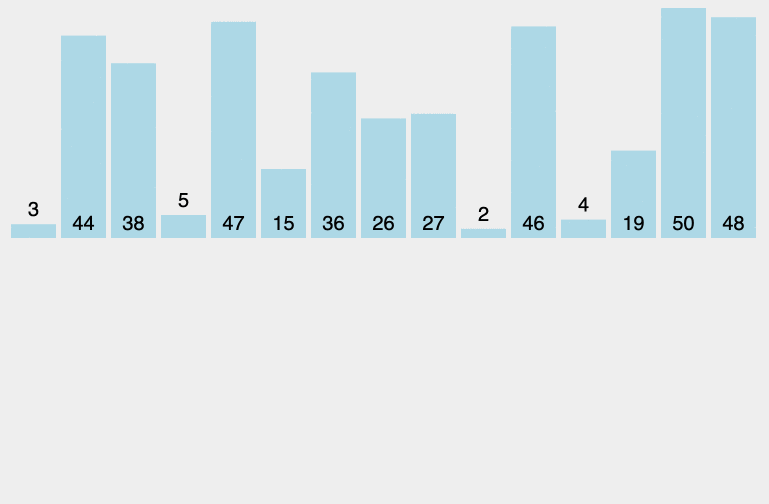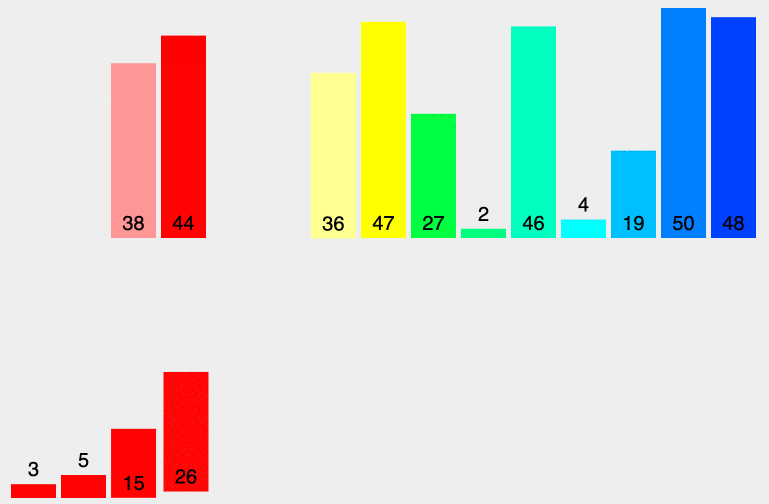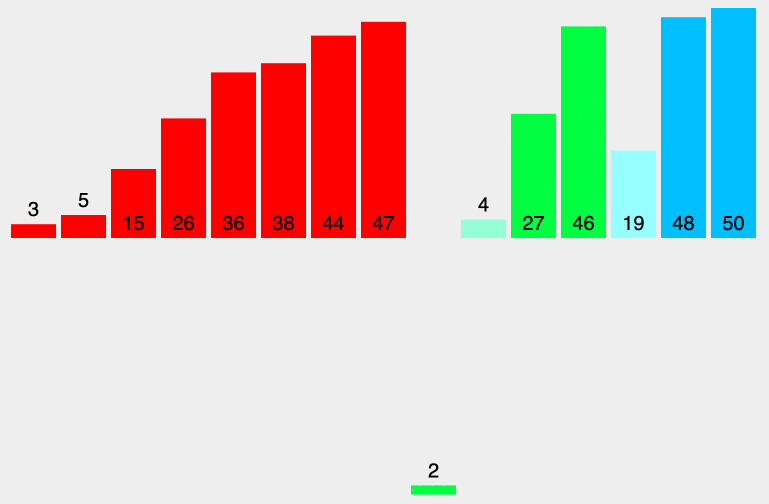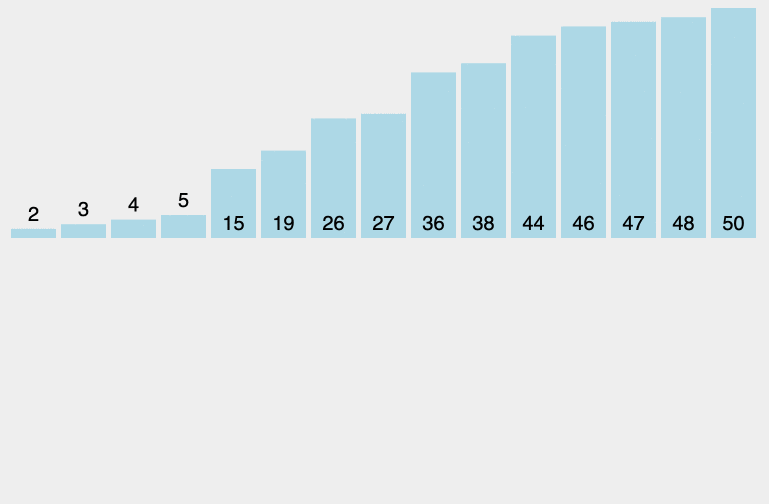
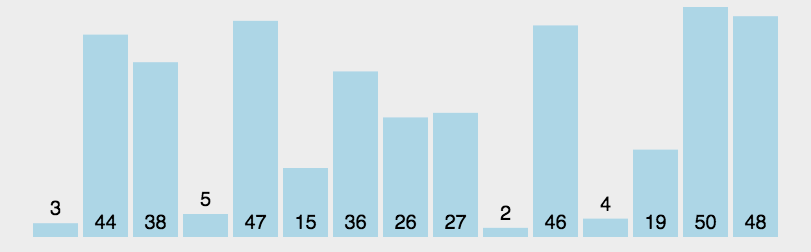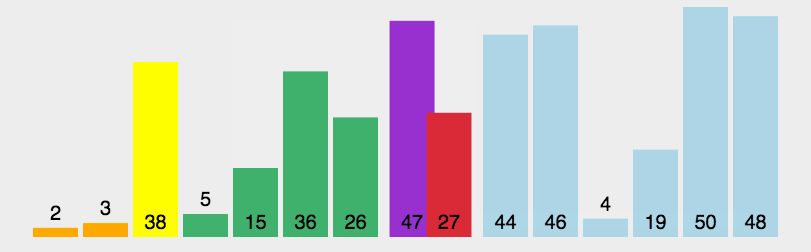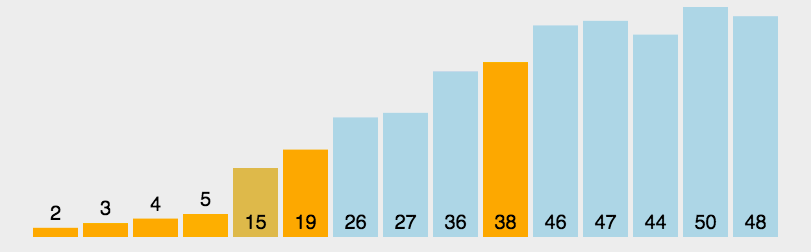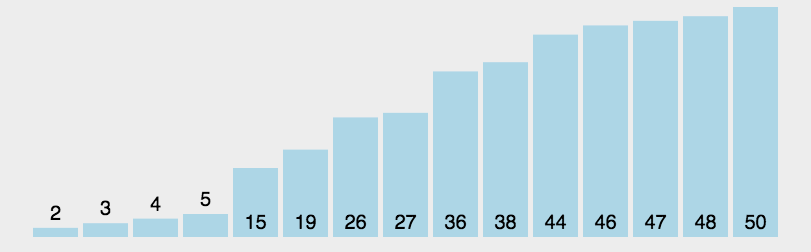
原理:从左至右选出数组中的最小的元素,并与最左边未排好序的第一个元素进行交换,此为 1 次选择排序过程。重复该过程 n 次,排序完成,其中 n 为数组长度。
选择排序源码
publicclassSelectionSort{ /** * 选择排序 * * @param nums */ publicvoidselectionSort(int[] nums){ int len = nums.length; if (len > 1) { for (int i = 0; i < len; i++) { // 最小元素索引。 int index = i; for (int j = i + 1; j < len; j++) { if (nums[j] < nums[index]) index = j; } swap(nums, i, index); } } }
publicvoidswap(int[] nums, int i, int j){ int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp; } }
/** * 迭代版快排 * * @param nums */ publicvoidquickSortIterator(int[] nums){ int len = nums.length; LinkedList<Interval> s = new LinkedList<Interval>(); s.push(new Interval(0, len - 1)); while (!s.isEmpty()) { Interval e = s.pop(); int start = e.start, end = e.end; if (start < end) { int index = partition(nums, start, end); s.push(new Interval(start, index - 1)); s.push(new Interval(index + 1, end)); } } }
/** * 分区操作 * * @param nums * @param start * @param end * @return 基准元素的位置 */ publicintpartition(int[] nums, int start, int end){ int left = start, right = end; int pivot = nums[end];
// 每次循环先从左至右遍历,找到比基准元素大的第一个元素,然后从右至左遍历,找到比基准元素小的第一个元素, // 最后交换两个元素的位置,循环终止时 left==right,且 left 指向第一个大于该基准元素的位置。 while (left < right) { while (left < right && nums[left] < pivot) left++; while (left < right && nums[right] >= pivot) right--; swap(nums, left, right); } // 交换基准元素与第一个大于基准的元素的位置。 swap(nums, left, end); return left; }
publicvoidswap(int[] nums, int i, int j){ int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp; } }
publicclassHeapSort{ /** * 堆排序 * * @param nums * @return */ publicvoidheapSort(int[] nums){ int len = nums.length; // 建堆操作。 for (int i = (len - 1) / 2; i >= 0; i--) { maxHeap(nums, i, len); // minHeap(nums, i, len); } // 排序操作。 for (int i = len - 1; i >= 0; i--) { swap(nums, 0, i); maxHeap(nums, 0, i); // minHeap(nums, 0, i); } }
/** * 最大堆调整操作 * * @param nums * @param parent 父节点 * @param len 堆的大小 */ publicvoidmaxHeap(int[] nums, int parent, int len){ int max = parent, left = parent * 2 + 1; int right = left + 1; if (left < len && nums[left] > nums[max]) max = left; if (right < len && nums[right] > nums[max]) max = right; if (parent != max) { swap(nums, parent, max); maxHeap(nums, max, len); } }
/** * 最小堆调整操作 * * @param nums * @param parent 父节点 * @param len 堆的大小 */ publicvoidminHeap(int[] nums, int parent, int len){ int min = parent, left = parent * 2 + 1; int right = left + 1; if (left < len && nums[left] < nums[min]) min = left; if (right < len && nums[right] < nums[min]) min = right; if (parent != min) { swap(nums, parent, min); minHeap(nums, min, len); } }
publicvoidswap(int[] nums, int i, int j){ int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp; } }
堆排序动态排序图
堆排序分析
从代码可知,堆排序分为建堆和调整两部分。在建堆的过程中,完全二叉树的高度为 k=log(n),第 i 层调整所需要的时间为节点个数 2^(i-1) 乘以要调整的高度 k-i,建堆所需的整体时间为每一层的时间相加,最终其时间复杂度趋近于 O(n)。在堆调整的过程中,每次调整需要的时间即为堆的层数 k,共需调整 n 次,累加所有调整的时间,其时间复杂度趋近于 O(n log n)。所以堆排序的整体时间复杂度为二者相加也趋近于 O(n log n)。
publicclassCountingSort{ /** * 稳定版计数排序 * * @param nums */ publicvoidcountingSort(int[] nums){ int len = nums.length; if (len > 1) { int min = nums[0], max = nums[0]; // 获取最小和最大元素值。 for (int i = 1; i < len; i++) { min = Math.min(min, nums[i]); max = Math.max(max, nums[i]); } // 计算每个元素出现的次数。 int k = max - min + 1; int[] count = newint[k]; for (int i = 0; i < len; i++) { count[nums[i] - min]++; } // 计算每个元素在排序数组中的位置。 for (int i = 1; i < k; i++) { count[i] += count[i - 1]; } // 反向填充,保证稳定性。 int[] extra = newint[len]; for (int i = len - 1; i >= 0; i--) { extra[--count[nums[i] - min]] = nums[i]; } // 拷贝回原数组。 for (int i = 0; i < len; i++) { nums[i] = extra[i]; } } }
/** * 优化版计数排序 * * @param nums */ publicvoidcountingSortOptimize(int[] nums){ int len = nums.length; if (len > 1) { int min = nums[0], max = nums[0]; for (int i = 1; i < len; i++) { min = Math.min(min, nums[i]); max = Math.max(max, nums[i]); } int k = max - min + 1; int[] count = newint[k]; for (int i = 0; i < len; i++) { count[nums[i] - min]++; } int index = 0; for (int i = 0; i < k; i++) { while (count[i] != 0) { nums[index++] = i + min; count[i]--; } } } } }